前言
CNN+ATT 是一种基于语句级别选择性注意力机制 的神经网络模型 , 用于构建基于远程监督 的关系抽取 系统.它是一个著名的神经关系抽取 (Neural Relation Extraction, NRE) 模型。
本博文是 CNN+ATT 原论文学习笔记,包括代码实现。
CNN+ATT 原论文链接:Neural Relation Extraction with Selective Attention over Instances .
代码仓库地址 : https://github.com/LuYF-Lemon-love/susu-knowledge-graph/tree/main/neural-relation-extraction/C%2B%2B .
操作系统:Ubuntu 18.04.6 LTS
参考文档
Neural Relation Extraction with Selective Attention over Instances (Lin et al., ACL 2016).
NRE .
Mike Mintz, Steven Bills, Rion Snow, and Dan Jurafsky. 2009. Distant supervision for relation extraction without labeled data. In Proceedings of ACL-IJCNLP, pages 1003–1011.
Daojian Zeng, Kang Liu, Yubo Chen, and Jun Zhao. 2015. Distant supervision for relation extraction via piecewise convolutional neural networks. In Proceedings of EMNLP.
知识图谱与深度学习, 作者 刘知远, 韩旭, 孙茂松, 由 清华大学出版社 出版, 书号 978-7-302-53852-3, 豆瓣链接: https://book.douban.com/subject/35093204/ .
Daojian Zeng, Kang Liu, Siwei Lai, Guangyou Zhou, and Jun Zhao. 2014. Relation classification via convolutional deep neural network. In Proceedings of COLING, pages 2335–2344.
Nitish Srivastava, Geoffrey Hinton, Alex Krizhevsky, Ilya Sutskever, and Ruslan Salakhutdinov. 2014. Dropout: A simple way to prevent neural networks from overfitting. JMLR, 15(1):1929–1958.
Sebastian Riedel, Limin Yao, and Andrew McCallum. 2010. Modeling relations and their mentions without labeled text. In Proceedings of ECML-PKDD, pages 148–163.
https://code.google.com/p/word2vec/ .
CNN+ATT 原论文学习笔记
Neural Relation Extraction with Selective Attention over Instances (基于语句级别选择性注意力机制的神经网络模型) 提出于 2016 年, 发表于 Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) .
远程监督关系抽取 已经广泛地应用于从文本 中发现新型的关系事实 . 然而, 远程监督不可避免的伴随着错误标注 的问题, 这些嘈杂的数据 将大大损害关系抽取的性能.
基于语句级别选择性注意力机制的关系出抽取神经网络模型 能够缓解远程监督关系抽取 的错误标签 问题, 该模型使用卷机神经网络 来嵌入句子的语义 . 之后, 使用语句级别选择性注意力 来动态地降低嘈杂实例 (句子) 的权重 .
实验结果证明, 该模型可以充分利用每个句子的所有信息, 有效的减少了错误标记实例 (句子) 的影响.
介绍 最近几年, 各种大型知识库 (Freebase , DBpedia , YAGO ) 已经被建立和广泛地应用于许多自然语言处理 (natural language processing, NLP) 任务, 包括 web search 和 question answering . 这些知识库是由大量三元组 (格式为 (Microsoft , founder , Bill Gates )) 组成的.
关系抽取 (relation extraction, RE) —— 从纯文本生成关系数据的过程, 是一个自然语言处理的重要任务.
(Mintz et al., 2009)3 远程监督 , 通过对齐知识库和纯文本 自动生成训练数据. 远程监督假设, 如果两个实体在知识库中存在某种关系, 则包含这两个实体的所有句子都将表达这种关系 . 例如, 三元组 (Microsoft, founder, Bill Gates ) 是知识库中的关系事实, 远距离监督会把包含这两个实体的所有句子 都视为关系 founder “Bill Gates ’s turn to philanthropy was linked to the antitrust problems Microsoft had in the U.S. and the European union.” (比尔·盖茨转向慈善事业与微软在美国和欧盟的反垄断问题有关。) 这句话并没有表达关系 founder , 但仍然视为一个正例 (关系 founder ).
因此有很多人 (2010 年, 2011 年, 2012 年) 采用多实例学习 (multi-instance learning ) 缓解远程监督错误标注的问题. (Zeng et al., 2015)4 多实例学习 与神经网络模型 相结合进一步缓解该问题. 该方法假设至少有一个提到这两个实体的句子 将表达它们之间的关系 , 并且只在训练和预测中为每个实体对选择最有可能的句子 . 该方法将丢失大量包含在被忽视的句子中的丰富信息 .
本论文提出了一种基于句子级注意力的卷积神经网络 (CNN) 用于远程监督关系提取 . 该模型使用 CNN 来嵌入句子的语义, 如下图. 之后, 为了利用每个句子的所有信息, 将关系表示为句子嵌入的语义组合 . 为了解决远程监督带来的错误标注问题, 该模型在这些实例的语义向量 上构建语句级别的注意力机制 , 从而动态地减少 噪声实例所对应的权重, 同时提升 有效实例所对应的权重. 最后, 将利用注意力机制计算的权重与对应实例向量的加权求和 作为特征向量 来进行关系抽取.
该论文的贡献总结如下:
与现有的神经关系抽取模型 相比, 该模型可以充分利用每个实体对的所有实例 (句子) 的信息 .
为了解决远程监督的错误标注问题, 该论文提出选择性注意力机制来忽视噪声数据 .
实验表明, 选择注意力机制 对于两种 CNN 模型的关系抽取 是有益的.
相关工作
关系抽取 是一个重要的 NLP 任务, 很多人研究有监督的关系抽取. (Mintz et al., 2009)3 远程监督 , 通过对齐知识库和纯文本 自动生成训练数据.
(Riedel et al., 2010) models distant supervision for relation extraction as a multi-instance single-label problem .
(Hoffmann et al., 2011; Surdeanu et al., 2012) adopt multi-instance multi-label learning in relation extraction .
Multi-instance learning was originally proposed to address the issue of ambiguously-labelled training data when predicting the activity of drugs (Dietterich et al., 1997)
(Bunescu and Mooney, 2007) connects weak supervision with multi-instance learning and extends it to relation extraction.
所有基于特征的方法 严重依赖 NLP 工具生成的特征的质量 , 这将受到错误传播问题 (error propagation problem ) 的困扰.
deep learning (Bengio, 2009) has been widely used for various areas, including computer vision , speech recognition and so on.
NLP tasks (successfully applied):
part-of-speech tagging (Collobert et al., 2011)
sentiment analysis (dos Santos and Gatti, 2014)
parsing (Socher et al., 2013)
machine translation (Sutskever et al., 2014)
(Socher et al., 2012) uses a recursive neural network in relation extraction.They parse the sentences first and then represent each node in the parsing tree as a vector.
(Zeng et al., 20146 an end-to-end convolutional neural network for relation extraction .
(Xie et al., 2016) attempts to incorporate the text information of entities for relation extraction .
虽然深度学习的方法取得了极大的成功, 这些模型仍然在句子级别上抽取关系 , 并且缺乏足够的训练数据 . 此外, 传统方法的多实例学习策略不容易应用于神经网络模型 .
(Zeng et al., 2015)4 combines at-least-one multi-instance learning with neural network model to extract relations on distant supervision data. However, they assume that only one sentence is active for each entity pair . Hence, it will lose a large amount of rich information containing in those neglected sentences .
因此, 本论文提出了对多个实例 (句子) 的语句级别选择性注意力机制 , 它能充分利用每个实体对的所有实例 (句子) 的信息 .
The attention-based models have attracted a lot of interests of researchers recently.
The selectivity of attention-based models allows them to learn alignments between different modalities .
It has been applied to various areas:
image classification (Mnih et al., 2014)
speech recognition (Chorowski et al., 2014)
image caption generation (Xu et al., 2015)
machine translation (Bahdanau et al., 2014).
To the best of our knowledge, this is the first effort to adopt attention-based model in distant supervised relation extraction .
方法
给定一个句子集合 { x 1 , x 2 , ⋅ ⋅ ⋅ , x n } \{x_1,x_2,\cdot\cdot\cdot,x_n\} { x 1 , x 2 , ⋅ ⋅ ⋅ , x n } 两个相对应的实体 (头实体和尾实体) , 本论文的模型预测每个关系 r r r
模型包含两个部分:
语句编码器 (Sentence Encoder). 给定一个句子 x x x 提取句子的向量表示 x x x . (原始句子和句子的向量都用 x x x
选择性注意力机制 (Selective Attention over Instances). 当获取到所有实例 (句子) 的向量表示 后, 本论文的模型使用语句级别的选择性注意力机制 来选择那些能够真正表达对应关系 的语句, 并赋予其更高的权重.
语句编码器
如下图所示, CNN 将句子 x x x x x x 句子中的单词 被转换成稠密实值特征向量 (词嵌入, 实值: C/C++ 中的 float 类型, 32 位). 然后, 卷积层 , Max 池化层 和 非线性激活函数 被用来提取句子的向量表示 x x x .
输入表示
CNN 的输入是句子 x x x 原始单词 . 首先将单词 转换成低维向量 . 本论文的模型通过词嵌入矩阵 将输入的每一个单词 转换成一个向量 . 此外, 为了指定每个实体对的位置 , 为句子中的每个单词 使用了位置嵌入 .
词嵌入 (Word Embeddings ). 词嵌入 旨在将离散字符形式的单词 转换为连续向量空间中分布式表示 , 从而捕捉到单词句法和所对应的语义信息 . 给定一个包含 m m m x = { w 1 , w 2 , ⋅ ⋅ ⋅ , w m } x = \{w_1,w_2,\cdot\cdot\cdot,w_m\} x = { w 1 , w 2 , ⋅ ⋅ ⋅ , w m } w i w_i w i 实值向量 表示. 单词的表示 用一个词嵌入矩阵 V ∈ R d a × ∣ V ∣ V \in \mathbb{R}^{d^a\times\mid V\mid} V ∈ R d a × ∣ V ∣ 列向量 来编码, 其中 V V V 固定大小的词汇表 (单词的总数固定).
位置嵌入 (Position Embeddings ). 在关系抽取的任务中, 靠近目标实体的单词 通常具有决定目标实体间关系的信息 . 类似于 (Zeng et al., 2014)6 由实体对指定的位置嵌入 帮助 CNN 观察每一单词 相对头实体 或尾实体 的相对距离 , 位置嵌入被定义为当前词相对头实体或尾实体的相对距离的组合 . 例如, “Bill_Gates is the founder of Microsoft.” , 单词 “founder” 到头实体 “Bill_Gates” 的相对距离是 3 , 到尾实体 “Microsoft” 的相对距离是 2 .
上图中, 假定词嵌入的维度 d a d^a d a 3 , 位置嵌入的维度 d b d^b d b 1 . 最后, 将所有单词的词嵌入和位置嵌入 拼接 (concatenate ) 起来, 表示成一个向量序列 w = { w 1 , w 2 , ⋅ ⋅ ⋅ , w m } w = \{w_1,w_2,\cdot\cdot\cdot,w_m\} w = { w 1 , w 2 , ⋅ ⋅ ⋅ , w m } w i ∈ R d w_i \in \mathbb{R}^d w i ∈ R d d = d a + d b × 2 d = d^a + d^b \times 2 d = d a + d b × 2
卷积层, Max 池化层 和 非线性激活函数
在关系抽取中, 主要的挑战 是:
句子的长度是可变的 .
重要信息可能出现在句子的任何位置 .
因此, 应该利用所有的局部特征 , 并在全局范围上进行关系预测 . 可以使用一个卷积层 来融合所有局部特征 .
卷积层 首先使用一个在句子上滑动的长度为 l l l 提取局部特征 (一维卷积 ), 上图中, 假定滑动窗口的长度 是 3 . 然后, 通过一个 Max 池化层 合并所有的局部特征 , 进而为每一个输入的句子 得到一个固定大小的向量 .
卷积 被定义为一个向量序列 w w w 一个卷积矩阵 W ∈ R d c × ( l × d ) W \in \mathbb{R}^{d^c \times (l \times d)} W ∈ R d c × ( l × d ) d c d^c d c 句子嵌入的维度 . 向量 q i ∈ R l × d q_i \in \mathbb{R}^{l \times d} q i ∈ R l × d i i i 词嵌入 w w w 的拼接 .
q i = w i − l + 1 : i ( 1 ≤ i ≤ m + l − 1 ) . (1) q_i = w_{i - l + 1 : i}\quad\quad(1 \leq i \leq m + l - 1). \tag{1}
q i = w i − l + 1 : i ( 1 ≤ i ≤ m + l − 1 ) . ( 1 )
当窗口在边界附近滑动 时, 它可能在句子边界之外 , 因此, 为句子 设置了特殊的填充标记 . 意味着将所有超出范围的输入向量 w i ( i < 1 o r i > m ) w_i(i < 1\quad or\quad i > m) w i ( i < 1 or i > m ) 零向量 .
卷积层的第 i i i
p i = [ W q + b ] i (2) p_i = [Wq + b]_i \tag{2}
p i = [ W q + b ] i ( 2 )
其中 b b b 句子向量 x ∈ R d c x \in \mathbb{R}^{d^c} x ∈ R d c i i i
[ x ] i = m a x ( p i ) , (3) [x]_i = max(p_i), \tag{3}
[ x ] i = ma x ( p i ) , ( 3 )
其中 [ x ] i [x]_i [ x ] i i i i 句子向量 x ∈ R d c x \in \mathbb{R}^{d^c} x ∈ R d c i i i p i p_i p i i i i i i i
进一步, PCNN (Zeng et al., 2015)4 CNN 的变体, 采用了分段 Max 池化操作来进行关系抽取, 每一个卷积输出 p i p_i p i ( p i 1 , p i 2 , p i 3 ) (p_{i1},p_{i2},p_{i3}) ( p i 1 , p i 2 , p i 3 ) 最大池化过程 分别在三个片段中执行. 定义如下:
[ x ] i j = m a x ( p i j ) , (4) [x]_{ij} = max(p_{ij}), \tag{4}
[ x ] ij = ma x ( p ij ) , ( 4 )
句子向量 [ x ] i [x]_i [ x ] i [ x ] i j [x]_{ij} [ x ] ij
最后, 是一个非线性激活函数 , 如双曲切线函数 (the hyperbolic tangent ).
双曲正切函数 (t a n h tanh t anh 双曲正弦函数 (s i n h sinh s inh 双曲余弦函数 (c o s h cosh cos h
t a n h x = s i n h x c o s h x = e x − e − x e x + e − x tanh x = \frac{sinh x}{cosh x} = \frac{e^x - e^{-x}}{e^x + e^{-x}}
t anh x = cos h x s inh x = e x + e − x e x − e − x
导数
( t a n h x ) ′ = s e c h 2 x = 1 c o s h 2 x = 1 − t a n h 2 x (tanh x)^{'} = sech^2x = \frac{1}{cosh^2x} = 1 - tanh^2x
( t anh x ) ′ = sec h 2 x = cos h 2 x 1 = 1 − t an h 2 x
图像
面向多实例的选择性注意力机制
假设有一个包含 n n n S = { x 1 , x 2 , ⋅ ⋅ ⋅ , x n } S = \{x_1,x_2,\cdot\cdot\cdot,x_n\} S = { x 1 , x 2 , ⋅ ⋅ ⋅ , x n } 实体对 ( h e a d , t a i l ) (head,tail) ( h e a d , t ai l )
为了利用所有句子的信息 , 本论文的模型在预测关系 r r r 实值向量 s s s S S S S S S x 1 , x 2 , ⋅ ⋅ ⋅ , x n x_1,x_2,\cdot\cdot\cdot,x_n x 1 , x 2 , ⋅ ⋅ ⋅ , x n x i x_i x i x i x_i x i ( h e a d , t a i l ) (head,tail) ( h e a d , t ai l ) r r r
集合向量 s s s x i x_i x i
s = ∑ i a i x i , (5) s = \sum_i a_ix_i, \tag{5}
s = i ∑ a i x i , ( 5 )
其中 a i a_i a i x i x_i x i
本论文中, a i a_i a i
Average: 假定所有的句子对于 s s s S S S s s s
s = ∑ i 1 n x i , (6) s = \sum_i \frac{1}{n}x_i, \tag{6}
s = i ∑ n 1 x i , ( 6 )
这是选择性注意力机制最朴素的基线 .
Selective Attention: 远程监督不可避免的带来错误标注 的问题, 因此, 如果简单将每个句子视为等价的 , 错误标注的句子将在训练和测试过程中带来大量的噪声 . 因此, 本论文的模型使用选择性注意力机制降噪 (de-emphasize the noisy sentence ). a i a_i a i
a i = e x p ( e i ) ∑ k e x p ( e k ) (7) a_i = \frac{exp(e_i)}{\sum_kexp(e_k)} \tag{7}
a i = ∑ k e x p ( e k ) e x p ( e i ) ( 7 )
其中, e i e_i e i 基于查询 (query-based) 的函数 , 它对输入句子 x i x_i x i r r r . 本论文的模型选择在不同替代方案中实现最佳性能的双线性形式 (the bilinear form):
e i = x i A r , (8) e_i = x_iAr, \tag{8}
e i = x i A r , ( 8 )
其中, A A A 加权对角矩阵 (a weighted diagonal matrix), r r r r r r r r r
最终, 通过一个 softmax 层定义了条件概率 p ( r ∣ S , θ ) p(r\mid S, θ) p ( r ∣ S , θ )
p ( r ∣ S , θ ) = e x p ( o r ) ∑ k = 1 n r e x p ( o k ) , (9) p(r\mid S, θ) = \frac{exp(o_r)}{\sum_{k=1}^{n_r} exp(o_k)}, \tag{9}
p ( r ∣ S , θ ) = ∑ k = 1 n r e x p ( o k ) e x p ( o r ) , ( 9 )
其中, n r n_r n r 关系的总数 , o o o 最终输出 , 它表示对所有关系类型 的预测评分 , 被定义为:
o = M s + d . (10) o = Ms + d. \tag{10}
o = M s + d . ( 10 )
其中 d ∈ R n r d \in \mathbb{R}^{n_r} d ∈ R n r 偏置向量 , M M M 所有关系类型的表示矩阵 (即所有关系类型对应的特征向量 所构成的矩阵 ).
(Zeng et al., 2015)4 at least one mention of the entity pair will reflect their relation , and only uses the sentence with the highest probability in each set for training . Hence, the method which they adopted for multi-instance learning can be regarded as a special case as our selective attention when the weight of the sentence with the highest probability is set to 1 and others to 0 .
优化和实现细节
目标函数 . 交叉熵误差 (cross entropy error), 定义如下:
J ( θ ) = ∑ i = 1 s l o g p ( r i ∣ S i , θ ) , (11) J(θ) = \sum_{i=1}^{s} log p(r_i \mid S_i, θ), \tag{11}
J ( θ ) = i = 1 ∑ s l o g p ( r i ∣ S i , θ ) , ( 11 )
其中, s s s θ θ θ r i r_i r i i i i i i i S i S_i S i i i i i i i 随机梯度下降 (stochastic gradient descent, SGD ). 从训练集中随机选择一个小批次 (mini-batch) 迭代训练直到模型收敛.
在最终的输出层使用 dropout (Srivastava et al., 2014)7 过拟合 . dropout 被定义为与一个向量 h h h 对应元素的乘法 (element-wise multiplication ), 该向量的元素是概率为 p p p Bernoulli random variables ), 因此公式 ( 10 ) (10) ( 10 )
o = M ( s ∘ h ) + d . (12) o = M(s \circ h) + d. \tag{12}
o = M ( s ∘ h ) + d . ( 12 )
在测试阶段, 学习到的集合表示被 p p p s i ^ = p s i \hat{s_i} = ps_i s i ^ = p s i o i ^ \hat{o_i} o i ^
实验
Our experiments are intended to demonstrate that our neural models with sentence-level selective attention can alleviate the wrong labelling problem and take full advantage of informative sentences for distant supervised relation extraction .
数据集和评测指标
在关系抽取任务中, (Riedel et al., 2010)8 Freebase 知识图谱中的世界知识与 <<纽约时报>> 语料库 (NYT) 中的语料进行对齐而生成的 (This dataset was generated by aligning Freebase relations with the New York Times corpus (NYT)). 实体是使用斯坦福大学命名实体标记器 找到的, 并进一步与 Freebase 实体名称相匹配 (Entity mentions are found using the Stanford named entity tagger (Finkel et al., 2005), and are further matched to the names of Freebase entities). 数据集包含两部分: 训练集 和测试集 . 对齐了 2005-2006 年语料库中的句子, 并将它们视为训练实例 . 测试实例 是 2007 年的对齐句子. 整个数据集合包含 53 种关系类型, 包含一种特殊类型关系 —— NA , 其表示头尾实体之间没有明确定义关系.
number of sentences number of entity pairs number of relational facts (not NA) number of sentences / number of entity pairs
training set 522,611
281,270
18,252
1.86
testing set 172,448
96,678
1,950
1.78
通过比较模型在测试集中挖掘出的世界知识与 Freebase 中的世界知识的重合度来评估关系抽取效果.
we evaluate our model in the held-out evaluation . It evaluates our model by comparing the relation facts discovered from the test articles with those in Freebase .
It assumes that the testing systems have similar performances in relation facts inside and outside Freebase.
Hence, the held-out evaluation provides an approximate measure of precision without time consumed human evaluation .
具体的模型性能则通过精度——召回率曲线 (the aggregate curves precision/recall curves)和 最高置信度预测精度 (Precision@N, P@N ) 来体现.
实验设置
词嵌入
使用 word2vec 9 NYT 语料库 训练词嵌入 . 将语料库 中出现超过 100 次的单词 保留为词汇 . 当一个实体有多个单词时, 连接 (concatenate ) 它的单词.
参数设置
在训练集 上使用三折交叉验证 (three-fold validation ) 调整模型, 使用网格搜索 (grid search) 确定最优参数.
对于训练 , 将所有训练数据 的迭代次数 设置为 25 .
最优超参数设置如下:
参数
值
卷积窗口大小 l l l
3
句子表示维度 d c d^c d c
230
词向量维度 d a d^a d a
50
位置向量维度 d b d^b d b
5
训练批次大小 B B B
160
学习率 λ \lambda λ
0.01
Dropout probability p p p
0.5
选择性注意力机制的有效性验证
为了证明语句级别选择性注意力机制的有效性, 通过保留评估 ( held-out evaluation ) 比较不同的方法. 选择 Zeng 等人4 6 卷积神经网路模型 CNN 及其变种模型 PCNN 作为句子编码器 (implement them by ourselves which achieve comparable results as the authors reported). 作者将两种不同类型的卷积神经网络分别与句子级别注意力机制 ATT、ATT 的基线版本 AVE (在该版本中, 每个实例集合的向量表示为集合内部实例的平均向量) 及 Zeng 等人4 多实例学习方法 ONE 进行了结合, 并比较了它们的表现.
句子编码器 :
the CNN model proposed in (Zeng et al., 2014)6
the PCNN model proposed in (Zeng et al., 2015)4
比较了两种 CNN , 它们带有句子级别注意力机制的版本 (ATT) , 它们的朴素版本 (AVE) , 它们的多实例学习方法 4 表现 .
Precion/recall curves of CNN, CNN+ONE, CNN+AVE, CNN+ATT
Precion/recall curves of PCNN, PCNN+ONE, PCNN+AVE, PCNN+ATT
从上图, 作者得到了如下观察结果:
对于 CNN 和 PCNN, ONE 方法与 CNN/PCNN 相比具有更好的性能. 原因在于原始的基于远程监督得到的训练数据包含大量的噪声数据, 而噪声数据会损害关系抽取的性能. ONE 方法引入多实例学习, 这在一定程度上减缓了该问题.
对于 CNN 和 PCNN, 与 CNN/PCNN 相比, AVE 方法对关系抽取模型的效果提升是有作用的. 这表明考虑更多的实例有利于关系抽取, 因为噪声信息可以通过信息的互补来减少负面影响, 更多的实例也带来了更多的信息.
对于 CNN 和 PCNN, AVE 方法与 ONE 方法相比具有相似的性能. 这说明, 尽管 AVE 方法引入了更多的实例信息, 但由于它将每个句子赋予同等的权重, 它也会从错误标注的语句中得到负面的噪声信息, 从而损害关系抽取的性能. 所以 AVE 方法与 ONE 方法难以分出优劣.
对于 CNN 和 PCNN, 与包括 AVE 方法在内的其他方法相比, ATT 方法在整个召回范围内实现了最高的精度. 它表明, 所提出的选择性注意力机制 是有益的. 它可以有效地滤除无意义的句子, 解决基于远程监督的关系抽取中的错误标注问题, 并尽可能地充分利用每一个实例的信息进行关系抽取.
实例数量的影响分析
在原始测试数据集中, 有 74,857 个实体对仅对应于一个句子, 几乎占所有实体对的 3/4. 由于选择性注意力机制的优势在于处理包含多个实例的实体对, 所以实验比较了 CNN/PCNN+ONE、CNN/PCNN+AVE、以及采用了注意力机制的 CNN/PCNN+ATT 在具有不同实例数量的实体对集合上的表现. 具体有以下 3 个实验场景.
One : 对于每个测试实体对, 随机选择其对应的实例集合中的一个实例, 并将这个实例用作关系预测.
Two : 对于每个测试实体对, 随机选择其对应的实例集合中的两个实例, 并将这两个实例用作关系预测.
All : 对于每个测试实体对, 使用其对应的实例集合中的所有实例进行关系预测.
值得注意的是 , 在训练过程中, 使用了所有实例所有预测中评分最高的 N 项预测的预测精度 P@N, 具体有 P@100、P@200、P@300 及它们的平均值. 各个模型在实体对拥有不同实例数目情况下的 P@N 的效果对比如下表所示.
从上表中, 可以观察到:
对于 CNN 和 PCNN, ATT 方法在所有测试设置中均达到最佳性能. 它表明了句子级选择性注意力机制对于多实例学习的有效性.
对于 CNN 和 PCNN, AVE 方法在 One 测试设置下, 效果与 ATT 方法相当. 然而, 当每个实体对的测试实例数量增加时, AVE 方法的性能几乎没有改善. 随着实例的增加, 它甚至在 P@100、P@200 中逐渐下降. 原因在于, 由于 AVE 方法对每个实例同等看待, 实例包含的不表达任何关系的噪声数据对于关系抽取的表现会产生负面影响.
在 One 测试设置下, CNN+AVE 和 CNN+ATT 与 CNN+ONE 相比有 5 ~ 8 个百分点的改进. 每个实体对在这个测试设置中只有一个实例, 这些方法的唯一区别来自训练方式的不同. 因此, 实验结果表明利用所有的实例会带来更多的信息, 尽管这也可能带来一些额外的噪声. 这些附带的信息在训练过程中提升了模型效果.
对于 CNN 和 PCNN, ATT 方法在 Two 和 All 测试设置中优于其他两个基线 (over 5% and 9%). 这表明, 通过考虑更多有用的信息, CNN+ATT 排名较高的关系事实更可靠, 更有利于关系提取.
与基于人工特征工程的方法的性能比较
为了验证所提出的方法, 作者选择了以下 3 种基于人工特征的方法来进行性能比较.
Mintz (Mintz et al., 2009) 是一个传统的基于远程监督的模型.
MultiR (Hoffmann et al., 2011) 提出了一个概率图模型用于多实例学习, 它的特点在于可以处理关系类型之间的重合.
MIML (Surdeanu et al., 2012) 同时考虑了多实例和多关系类型两种情况 (即每个实体对可能有多个句子, 也可能有多个关系类型).
We implement them with the source codes released by the authors.
每个方法的精度-召回率曲线如下图所示.
从上图中, 可以观察到:
在整个召回率范围内, CNN/PCNN+ATT 显著优于 所有基于人工特征的方法. 当召回率 > 0.1 时, 基于特征的方法的性能迅速下降. 相比之下, 在召回率达到约 0.3 之前, 该论文的模型都具有合理的准确率. 这表明人工设计的特征不能简洁地表达实例的语义含义, 而自然语言处理工具带来的错误则会损害关系抽取的性能. 相比之下, 可以自主学习每个实例向量表示的 CNN/PCNN+ATT 模型可以很好地表达每个实例的语义信息.
在整个召回率范围内, PCNN+ATT 与 CNN+ATT 相比表现要好得多. 这意味着选择性注意力机制可以很好地考虑所有实例的全局信息, 但无法使模型对于单个实例的理解和表示变好. 因此, 如果有更好的句子编码器, 那么模型的性能可以进一步提高.
案例分析
下表显示了测试数据中选择性注意力机制的两个示例. 对于每个关系, 展示了其对应的拥有高注意力权值的句子和拥有低注意力权值的句子, 并且对每个实体对都进行了加粗显示.
From the table we find that: The former example is related to the relation employer of. The sentence with low attention weight does not express the relation between two entities, while the high one shows that Mel Karmazin is the chief executive of Sirius Satellite RadioThe later example is related to the relation place of birth. The sentence with low attention weight expresses where Ernst Haefliger is died in, while the high one expresses where he is born in.
Conclusion and Future Works
In this paper, we develop CNN with sentence-level selective attention. Our model can make full use of all informative sentences and alleviate the wrong labelling problem for distant supervised relation extraction. In experiments, we evaluate our model on relation extraction task. The experimental results show that our model significantly and consistently outperforms state-of-the-art feature-based methods and neural network methods.
In the future, we will explore the following directions:
Our model incorporates multi-instance learning with neural network via instance-level selective attention. It can be used in not only distant supervised relation extraction but also other multi-instance learning tasks. We will explore our model in other area such as text categorization.
CNN is one of the effective neural networks for neural relation extraction. Researchers also propose many other neural network models for relation extraction. In the future, we will incorporate our instance-level selective attention technique with those models for relation extraction.
代码实现
文件
代码仓库地址 : https://github.com/LuYF-Lemon-love/susu-knowledge-graph/tree/main/neural-relation-extraction/C%2B%2B .
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 $ tree . ├── CNN+ATT │ ├── clean.sh │ ├── init.h │ ├── output │ │ ├── attention_weights.txt │ │ ├── conv_1d.txt │ │ ├── position_vec.txt │ │ ├── pr.txt │ │ ├── relation_matrix.txt │ │ └── word2vec.txt │ ├── run.sh │ ├── test.cpp │ ├── test.h │ └── train.cpp ├── data │ ├── relation.txt │ ├── test.txt │ ├── train.txt │ └── vec.bin ├── data.zip ├── papers │ └── Neural Relation Extraction with Selective Attention over Instances.pdf └── README.md 4 directories, 19 files $
数据
NYT10
链接:https://pan.baidu.com/s/1SIswYS8vvuDAPiJd2L0d5A 提取码:g90p .
The original data of NYT10 can be downloaded from:
Relation Extraction: NYT10 is originally released by the paper “Sebastian Riedel, Limin Yao, and Andrew McCallum. Modeling relations and their mentions without labeled text.” [Download]
Pre-Trained Word Vectors are learned from New York Times Annotated Corpus (LDC Data LDC2008T19), which should be obtained from LDC (https://catalog.ldc.upenn.edu/LDC2008T19 ).
The train set is generated by merging all training data of manual and held-out datasets, deleted those data that have overlap with the test set, and used the remain one as our training data.
To run the code, the dataset should be put in the folder data/ using the following format, containing four files
train.txt : training file, format (fb_mid_e1, fb_mid_e2, e1_name, e2_name, relation, sentence).
test.txt : test file, same format as train.txt.
relation.txt : all relations, one per line.
vec.bin : the pre-train word embedding file.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 $ tree . ├── relation.txt ├── test.txt ├── train.txt └── vec.bin 0 directories, 4 files $ head relation.txtNA /location/neighborhood/neighborhood_of /location/fr_region/capital /location/cn_province/capital /location/in_state/administrative_capital /base/locations/countries/states_provinces_within /business/company/founders /location/country/languages_spoken /people/person/place_of_birth /people/deceased_person/place_of_death $ head test.txtm.01l443l m.04t_bj dave_holland barry_altschul NA the occasion was suitably exceptional : a reunion of the 1970s-era sam rivers trio , with dave_holland on bass and barry_altschul on drums . ###END### m.01l443l m.04t_bj dave_holland barry_altschul NA tonight he brings his energies and expertise to the miller theater for the festival 's thrilling finale : a reunion of the 1970s sam rivers trio , with dave_holland on bass and barry_altschul on drums . ###END### m.04t_bj m.01l443l barry_altschul dave_holland NA the occasion was suitably exceptional : a reunion of the 1970s-era sam rivers trio , with dave_holland on bass and barry_altschul on drums . ###END### m.04t_bj m.01l443l barry_altschul dave_holland NA tonight he brings his energies and expertise to the miller theater for the festival 's thrilling finale : a reunion of the 1970s sam rivers trio , with dave_holland on bass and barry_altschul on drums . ###END### m.0frkwp m.04mh_g ruth little_neck NA shapiro -- ruth of little_neck , ny . ###END### m.04mh_g m.0frkwp little_neck ruth NA shapiro -- ruth of little_neck , ny . ###END### m.02bv2x m.01w7tkh henry nicole NA cherished grandmother of henry , stephanie , harrison and jill shapiro and nicole and eric beinhorn . ###END### m.01w7tkh m.02bv2x nicole henry NA cherished grandmother of henry , stephanie , harrison and jill shapiro and nicole and eric beinhorn . ###END### m.0124lx m.07hjs9 lewis john_gross NA beloved wife of the late dr. frederick e. lane , and mother of joseph , ila lane gross , lewis , and edward ; mother-in-law of bobbi , john_gross , nancy , and judy . ###END### m.0124lx m.07hjs9 lewis john_gross NA beloved wife of the late dr. frederick e. lane , and mother of joseph , ila lane gross , lewis , and edward ; mother-in-law of bobbi , john_gross , nancy , and judy . ###END### $ head train.txtm.0ccvx m.05gf08 queens belle_harbor /location/location/contains sen. charles e. schumer called on federal safety officials yesterday to reopen their investigation into the fatal crash of a passenger jet in belle_harbor , queens , because equipment failure , not pilot error , might have been the cause . ###END### m.0ccvx m.05gf08 queens belle_harbor /location/location/contains but instead there was a funeral , at st. francis de sales roman catholic church , in belle_harbor , queens , the parish of his birth . ###END### m.0ccvx m.05gf08 queens belle_harbor /location/location/contains rosemary antonelle , the daughter of teresa l. antonelle and patrick antonelle of belle_harbor , queens , was married yesterday afternoon to lt. thomas joseph quast , a son of peggy b. quast and vice adm. philip m. quast of carmel , calif. . ###END### m.0ccvx m.05gf08 queens belle_harbor /location/location/contains one was for st. francis de sales roman catholic church in belle_harbor ; another board studded with electromechanical magnets will go under the pipes of an organ at the evangelical lutheran church of christ in rosedale , queens . ###END### m.0ccvx m.05gf08 queens belle_harbor /location/location/contains the firefighter , whom a fire department official identified as joseph moore , of belle_harbor , queens , was taken to newyork-presbyterian\/weill cornell hospital , where he was in critical but stable condition last night , the police said . ###END### m.0ccvx m.05gf08 queens belle_harbor /location/location/contains in st. francis de sales roman catholic church in belle_harbor , queens , the second verse of the opening hymn , '' be not afraid , '' seemed to connect katrina and sept. 11 : '' if you pass through raging waters in the sea , you shall not drown . ###END### m.0ccvx m.05gf08 queens belle_harbor /location/location/contains on nov. 12 , while walking his dog near his home in belle_harbor , queens , he saw a passenger plane plunge to the ground . ###END### m.0ccvx m.05gf08 queens belle_harbor /location/location/contains colm j. neilson , of belle_harbor , queens , said he thought the conductors ' role was overrated . '' ###END### m.0ccvx m.05gf08 queens belle_harbor /location/location/contains she is a daughter of marion i. rabbin and dr. murvin rabbin of belle_harbor , queens .###END### m.0ccvx m.05gf08 queens belle_harbor /location/location/contains he is a son of vera and william lichtenberg of belle_harbor , queens . ###END### $
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 $ tree . ├── clean.sh ├── init.h ├── output │ ├── attention_weights.txt │ ├── conv_1d.txt │ ├── position_vec.txt │ ├── pr.txt │ ├── relation_matrix.txt │ └── word2vec.txt ├── run.sh ├── test.cpp ├── test.h └── train.cpp 1 directory, 12 files $
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 269 270 271 272 273 274 275 276 277 278 279 280 281 282 283 284 285 286 287 288 289 290 291 292 293 294 295 296 297 298 299 300 301 302 303 304 305 306 307 308 309 310 311 312 313 314 315 316 317 318 319 320 321 322 323 324 325 326 327 328 329 330 331 332 333 334 335 336 337 338 339 340 341 342 343 344 345 346 347 348 349 350 351 352 353 354 355 356 357 358 359 360 361 362 363 364 365 366 367 368 369 370 371 372 373 374 375 376 377 378 379 380 381 382 383 384 385 386 387 388 389 390 391 392 393 394 395 396 397 398 399 400 401 402 403 404 405 406 407 408 409 #ifndef INIT_H #define INIT_H #include <cstdio> #include <cstdlib> #include <cmath> #include <cstring> #include <cfloat> #include <cassert> #include <pthread.h> #include <sys/time.h> #include <vector> #include <map> #include <string> #include <algorithm> #include <utility> #define INT int #define REAL float INT batch = 40 ; INT num_threads = 32 ; REAL alpha = 0.00125 ; REAL current_rate = 1.0 ; REAL reduce_epoch = 0.98 ; INT epochs = 25 ; INT limit = 30 ; INT dimension_pos = 5 ; INT window = 3 ; INT dimension_c = 230 ; REAL dropout_probability = 0.5 ; INT output_model = 0 ; std::string note = "" ; std::string data_path = "../data/" ; std::string output_path = "./output/" ; INT word_total, dimension; REAL *word_vec; std::map<std::string, INT> word2id; INT relation_total; std::vector<std::string> id2relation; std::map<std::string, INT> relation2id; INT position_min_head, position_max_head, position_min_tail, position_max_tail; INT position_total_head, position_total_tail; std::map<std::string, std::vector<INT> > bags_train; std::vector<INT> train_relation_list, train_length; std::vector<INT *> train_sentence_list, train_position_head, train_position_tail; std::map<std::string, std::vector<INT> > bags_test; std::vector<INT> test_relation_list, test_length; std::vector<INT *> test_sentence_list, test_position_head, test_position_tail; REAL *position_vec_head, *position_vec_tail; REAL *conv_1d_word, *conv_1d_position_head, *conv_1d_position_tail, *conv_1d_bias; std::vector<std::vector<std::vector<REAL> > > attention_weights; REAL *relation_matrix, *relation_matrix_bias; REAL *word_vec_copy, *position_vec_head_copy, *position_vec_tail_copy; REAL *conv_1d_word_copy, *conv_1d_position_head_copy, *conv_1d_position_tail_copy, *conv_1d_bias_copy; std::vector<std::vector<std::vector<REAL> > > attention_weights_copy; REAL *relation_matrix_copy, *relation_matrix_bias_copy; void init () printf ("\n##################################################\n\nInit start...\n\n" ); INT tmp; FILE *f = fopen ((data_path + "vec.bin" ).c_str (), "rb" ); tmp = fscanf (f, "%d" , &word_total); tmp = fscanf (f, "%d" , &dimension); word_vec = (REAL *)malloc ((word_total + 1 ) * dimension * sizeof (REAL)); word2id["UNK" ] = 0 ; for (INT i = 1 ; i <= word_total; i++) { std::string name = "" ; while (1 ) { char ch = fgetc (f); if (feof (f) || ch == ' ' ) break ; if (ch != '\n' ) name = name + ch; } word2id[name] = i; long long last = i * dimension; REAL sum = 0 ; for (INT a = 0 ; a < dimension; a++) { tmp = fread (&word_vec[last + a], sizeof (REAL), 1 , f); sum += word_vec[last + a] * word_vec[last + a]; } sum = sqrt (sum); for (INT a = 0 ; a < dimension; a++) word_vec[last + a] = word_vec[last + a] / sum; } word_total += 1 ; fclose (f); char buffer[1000 ]; f = fopen ((data_path + "relation.txt" ).c_str (), "r" ); while (fscanf (f, "%s" , buffer) == 1 ) { relation2id[(std::string)(buffer)] = relation_total++; id2relation.push_back ((std::string)(buffer)); } fclose (f); position_min_head = 0 ; position_max_head = 0 ; position_min_tail = 0 ; position_max_tail = 0 ; f = fopen ((data_path + "train.txt" ).c_str (), "r" ); while (fscanf (f, "%s" , buffer) == 1 ) { std::string e1 = buffer; tmp = fscanf (f, "%s" , buffer); std::string e2 = buffer; tmp = fscanf (f, "%s" , buffer); std::string head_s = (std::string)(buffer); tmp = fscanf (f, "%s" , buffer); std::string tail_s = (std::string)(buffer); tmp = fscanf (f, "%s" , buffer); bags_train[e1 + "\t" + e2 + "\t" + (std::string)(buffer)].push_back (train_relation_list.size ()); INT relation_id = relation2id[(std::string)(buffer)]; INT len_s = 0 , head_pos = 0 , tail_pos = 0 ; std::vector<INT> sentence; while (fscanf (f, "%s" , buffer) == 1 ) { std::string word = buffer; if (word == "###END###" ) break ; INT word_id = word2id[word]; if (word == head_s) head_pos = len_s; if (word == tail_s) tail_pos = len_s; len_s++; sentence.push_back (word_id); } train_relation_list.push_back (relation_id); train_length.push_back (len_s); INT *sentence_ptr = (INT *)calloc (len_s, sizeof (INT)); INT *sentence_head_pos = (INT *)calloc (len_s, sizeof (INT)); INT *sentence_tail_pos = (INT *)calloc (len_s, sizeof (INT)); for (INT i = 0 ; i < len_s; i++) { sentence_ptr[i] = sentence[i]; sentence_head_pos[i] = head_pos - i; sentence_tail_pos[i] = tail_pos - i; if (sentence_head_pos[i] >= limit) sentence_head_pos[i] = limit; if (sentence_tail_pos[i] >= limit) sentence_tail_pos[i] = limit; if (sentence_head_pos[i] <= -limit) sentence_head_pos[i] = -limit; if (sentence_tail_pos[i] <= -limit) sentence_tail_pos[i] = -limit; if (sentence_head_pos[i] > position_max_head) position_max_head = sentence_head_pos[i]; if (sentence_tail_pos[i] > position_max_tail) position_max_tail = sentence_tail_pos[i]; if (sentence_head_pos[i] < position_min_head) position_min_head = sentence_head_pos[i]; if (sentence_tail_pos[i] < position_min_tail) position_min_tail = sentence_tail_pos[i]; } train_sentence_list.push_back (sentence_ptr); train_position_head.push_back (sentence_head_pos); train_position_tail.push_back (sentence_tail_pos); } fclose (f); f = fopen ((data_path + "test.txt" ).c_str (), "r" ); while (fscanf (f, "%s" , buffer)==1 ) { std::string e1 = buffer; tmp = fscanf (f, "%s" , buffer); std::string e2 = buffer; tmp = fscanf (f, "%s" , buffer); std::string head_s = (std::string)(buffer); tmp = fscanf (f, "%s" , buffer); std::string tail_s = (std::string)(buffer); tmp = fscanf (f, "%s" , buffer); bags_test[e1 + "\t" + e2].push_back (test_relation_list.size ()); INT relation_id = relation2id[(std::string)(buffer)]; INT len_s = 0 , head_pos = 0 , tail_pos = 0 ; std::vector<INT> sentence; while (fscanf (f, "%s" , buffer) == 1 ) { std::string word = buffer; if (word=="###END###" ) break ; INT word_id = word2id[word]; if (head_s == word) head_pos = len_s; if (tail_s == word) tail_pos = len_s; len_s++; sentence.push_back (word_id); } test_relation_list.push_back (relation_id); test_length.push_back (len_s); INT *sentence_ptr=(INT *)calloc (len_s, sizeof (INT)); INT *sentence_head_pos=(INT *)calloc (len_s, sizeof (INT)); INT *sentence_tail_pos=(INT *)calloc (len_s, sizeof (INT)); for (INT i = 0 ; i < len_s; i++) { sentence_ptr[i] = sentence[i]; sentence_head_pos[i] = head_pos - i; sentence_tail_pos[i] = tail_pos - i; if (sentence_head_pos[i] >= limit) sentence_head_pos[i] = limit; if (sentence_tail_pos[i] >= limit) sentence_tail_pos[i] = limit; if (sentence_head_pos[i] <= -limit) sentence_head_pos[i] = -limit; if (sentence_tail_pos[i] <= -limit) sentence_tail_pos[i] = -limit; if (sentence_head_pos[i] > position_max_head) position_max_head = sentence_head_pos[i]; if (sentence_tail_pos[i] > position_max_tail) position_max_tail = sentence_tail_pos[i]; if (sentence_head_pos[i] < position_min_head) position_min_head = sentence_head_pos[i]; if (sentence_tail_pos[i] < position_min_tail) position_min_tail = sentence_tail_pos[i]; } test_sentence_list.push_back (sentence_ptr); test_position_head.push_back (sentence_head_pos); test_position_tail.push_back (sentence_tail_pos); } fclose (f); for (INT i = 0 ; i < train_position_head.size (); i++) { INT len_s = train_length[i]; INT *position = train_position_head[i]; for (INT j = 0 ; j < len_s; j++) position[j] = position[j] - position_min_head; position = train_position_tail[i]; for (INT j = 0 ; j < len_s; j++) position[j] = position[j] - position_min_tail; } for (INT i = 0 ; i < test_position_head.size (); i++) { INT len_s = test_length[i]; INT *position = test_position_head[i]; for (INT j = 0 ; j < len_s; j++) position[j] = position[j] - position_min_head; position = test_position_tail[i]; for (INT j = 0 ; j < len_s; j++) position[j] = position[j] - position_min_tail; } position_total_head = position_max_head - position_min_head + 1 ; position_total_tail = position_max_tail - position_min_tail + 1 ; printf ("训练数据和测试数据加载成功!\n\n" ); } void print_information () std::string save_model[] = {"不会保存模型." , "将会保存模型." }; printf ("batch: %d\nnumber of threads: %d\nlearning rate: %.8f\n" , batch, num_threads, alpha); printf ("init_rate: %.2f\nreduce_epoch: %.2f\nepochs: %d\n\n" , current_rate, reduce_epoch, epochs); printf ("word_total: %d\nword dimension: %d\n\n" , word_total, dimension); printf ("limit: %d\nposition_total_head: %d\nposition_total_tail: %d\ndimension_pos: %d\n\n" , limit, position_total_head, position_total_tail, dimension_pos); printf ("window: %d\ndimension_c: %d\n\n" , window, dimension_c); printf ("relation_total: %d\ndropout_probability: %.2f\n\n" , relation_total, dropout_probability); printf ("%s\nnote: %s\n\n" , save_model[output_model].c_str (), note.c_str ()); printf ("folder of data: %s\n" , data_path.c_str ()); printf ("folder of outputing results (precion/recall curves) and models: %s\n\n" , output_path.c_str ()); printf ("number of training samples: %7d - average sentence number of per training sample: %.2f\n" , INT (bags_train.size ()), float (float (train_sentence_list.size ()) / bags_train.size ())); printf ("number of testing samples: %7d - average sentence number of per testing sample: %.2f\n\n" , INT (bags_test.size ()), float (float (test_sentence_list.size ()) / bags_test.size ())); printf ("Init end.\n\n" ); } INT arg_pos (char *str, INT argc, char **argv) { INT a; for (a = 1 ; a < argc; a++) if (!strcmp (str, argv[a])) { if (a == argc - 1 ) { printf ("Argument missing for %s\n" , str); exit (1 ); } return a; } return -1 ; } REAL calc_tanh (REAL value) { if (value > 20 ) return 1.0 ; if (value < -20 ) return -1.0 ; REAL sinhx = exp (value) - exp (-value); REAL coshx = exp (value) + exp (-value); return sinhx / coshx; } INT get_rand_i (INT min, INT max) { INT d = max - min; INT res = rand () % d; if (res < 0 ) res += d; return res + min; } REAL get_rand_u (REAL min, REAL max) { return min + (max - min) * rand () / (RAND_MAX + 1.0 ); } #endif
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 269 270 271 272 273 274 275 276 277 278 279 280 281 282 283 284 285 286 287 288 289 290 291 292 293 294 295 296 297 298 299 300 301 302 303 304 305 306 307 308 309 310 311 312 313 314 315 316 317 318 319 320 321 322 323 324 325 326 327 328 329 330 331 332 333 334 335 336 337 #ifndef TEST_H #define TEST_H #include "init.h" std::vector<std::pair<std::string, std::pair<INT,double > > > predict_relation_vector; INT num_test_non_NA; std::vector<std::string> bags_test_key; std::vector<INT> thread_first_bags_test; pthread_mutex_t test_mutex;struct timeval test_start, test_end;bool cmp_predict_probability (std::pair<std::string, std::pair<INT,double > > a, std::pair<std::string, std::pair<INT,double > >b) return a.second.second > b.second.second; } std::vector<REAL> calc_conv_1d (INT *sentence, INT *test_position_head, INT *test_position_tail, INT sentence_length) std::vector<REAL> conv_1d_result_k; conv_1d_result_k.resize (dimension_c, 0 ); for (INT i = 0 ; i < dimension_c; i++) { INT last_word = i * window * dimension; INT last_pos = i * window * dimension_pos; REAL max_pool_1d = -FLT_MAX; for (INT last_window = 0 ; last_window <= sentence_length - window; last_window++) { REAL sum = 0 ; INT total_word = 0 ; INT total_pos = 0 ; for (INT j = last_window; j < last_window + window; j++) { INT last_word_vec = sentence[j] * dimension; for (INT k = 0 ; k < dimension; k++) { sum += conv_1d_word[last_word + total_word] * word_vec[last_word_vec + k]; total_word++; } INT last_pos_head = test_position_head[j] * dimension_pos; INT last_pos_tail = test_position_tail[j] * dimension_pos; for (INT k = 0 ; k < dimension_pos; k++) { sum += conv_1d_position_head[last_pos + total_pos] * position_vec_head[last_pos_head + k]; sum += conv_1d_position_tail[last_pos + total_pos] * position_vec_tail[last_pos_tail + k]; total_pos++; } } if (sum > max_pool_1d) max_pool_1d = sum; } conv_1d_result_k[i] = max_pool_1d + conv_1d_bias[i]; } for (INT i = 0 ; i < dimension_c; i++) conv_1d_result_k[i] = calc_tanh (conv_1d_result_k[i]); return conv_1d_result_k; } void * test_mode (void *thread_id) INT id; id = (unsigned long long )(thread_id); INT left = thread_first_bags_test[id]; INT right; if (id == num_threads-1 ) right = bags_test_key.size (); else right = thread_first_bags_test[id + 1 ]; std::map<INT,INT> sample_relation_list; for (INT i_sample = left; i_sample < right; i_sample++) { sample_relation_list.clear (); std::vector<std::vector<REAL> > conv_1d_result; INT bags_size = bags_test[bags_test_key[i_sample]].size (); for (INT k = 0 ; k < bags_size; k++) { INT i = bags_test[bags_test_key[i_sample]][k]; sample_relation_list[test_relation_list[i]] = 1 ; conv_1d_result.push_back (calc_conv_1d (test_sentence_list[i], test_position_head[i], test_position_tail[i], test_length[i])); } std::vector<float > result_final; result_final.resize (relation_total, 0.0 ); for (INT index_r = 0 ; index_r < relation_total; index_r++) { std::vector<REAL> weight; REAL weight_sum = 0 ; for (INT k = 0 ; k < bags_size; k++) { REAL s = 0 ; for (INT i_r = 0 ; i_r < dimension_c; i_r++) { REAL temp = 0 ; for (INT i_x = 0 ; i_x < dimension_c; i_x++) temp += conv_1d_result[k][i_x] * attention_weights[index_r][i_x][i_r]; s += temp * relation_matrix[index_r * dimension_c + i_r]; } s = exp (s); weight.push_back (s); weight_sum += s; } for (INT k = 0 ; k < bags_size; k++) weight[k] /= weight_sum; std::vector<REAL> result_sentence; result_sentence.resize (dimension_c); for (INT i = 0 ; i < dimension_c; i++) for (INT k = 0 ; k < bags_size; k++) result_sentence[i] += conv_1d_result[k][i] * weight[k]; std::vector<REAL> result_final_r; double temp = 0 ; for (INT i_r = 0 ; i_r < relation_total; i_r++) { REAL s = 0 ; for (INT i_s = 0 ; i_s < dimension_c; i_s++) s += dropout_probability * result_sentence[i_s] * relation_matrix[i_r * dimension_c + i_s]; s += relation_matrix_bias[i_r]; s = exp (s); temp += s; result_final_r.push_back (s); } result_final[index_r] = result_final_r[index_r]/temp; } pthread_mutex_lock (&test_mutex); for (INT i_r = 1 ; i_r < relation_total; i_r++) { predict_relation_vector.push_back (std::make_pair (bags_test_key[i_sample] + "\t" + id2relation[i_r], std::make_pair (sample_relation_list.count (i_r), result_final[i_r]))); } pthread_mutex_unlock (&test_mutex); } } void test () printf ("##################################################\n\nTest start...\n\n" ); gettimeofday (&test_start, NULL ); num_test_non_NA = 0 ; bags_test_key.clear (); thread_first_bags_test.clear (); predict_relation_vector.clear (); std::vector<INT> sample_sum; sample_sum.clear (); for (std::map<std::string, std::vector<INT> >::iterator it = bags_test.begin (); it != bags_test.end (); it++) { std::map<INT, INT> sample_relation_list; sample_relation_list.clear (); for (INT i = 0 ; i < it->second.size (); i++) { INT pos = it->second[i]; if (test_relation_list[pos] > 0 ) sample_relation_list[test_relation_list[pos]] = 1 ; } num_test_non_NA += sample_relation_list.size (); bags_test_key.push_back (it->first); sample_sum.push_back (it->second.size ()); } for (INT i = 1 ; i < sample_sum.size (); i++) sample_sum[i] += sample_sum[i - 1 ]; INT thread_id = 0 ; thread_first_bags_test.resize (num_threads + 1 ); for (INT i = 0 ; i < sample_sum.size (); i++) if (sample_sum[i] >= (sample_sum[sample_sum.size ()-1 ] / num_threads) * thread_id) { thread_first_bags_test[thread_id] = i; thread_id += 1 ; } printf ("Number of test samples for non NA relation: %d\n\n" , num_test_non_NA); pthread_t *pt = (pthread_t *)malloc (num_threads * sizeof (pthread_t )); for (long a = 0 ; a < num_threads; a++) pthread_create (&pt[a], NULL , test_mode, (void *)a); for (long a = 0 ; a < num_threads; a++) pthread_join (pt[a], NULL ); free (pt); std::sort (predict_relation_vector.begin (),predict_relation_vector.end (), cmp_predict_probability); REAL correct = 0 ; FILE* f = fopen ((output_path + "pr" + note + ".txt" ).c_str (), "w" ); INT top_2000 = std::min (2000 , INT (predict_relation_vector.size ())); for (INT i = 0 ; i < top_2000; i++) { if (predict_relation_vector[i].second.first != 0 ) correct++; REAL precision = correct / (i + 1 ); REAL recall = correct / num_test_non_NA; if ((i+1 ) % 50 == 0 ) printf ("precion/recall curves %4d / %4d - precision: %.3lf - recall: %.3lf\n" , (i + 1 ), top_2000, precision, recall); fprintf (f, "precision: %.3lf recall: %.3lf correct: %d predict_probability: %.2lf predict_triplet: %s\n" , precision, recall, predict_relation_vector[i].second.first, predict_relation_vector[i].second.second, predict_relation_vector[i].first.c_str ()); } fclose (f); gettimeofday (&test_end, NULL ); long double time_use = (1000000 * (test_end.tv_sec - test_start.tv_sec) + test_end.tv_usec - test_start.tv_usec) / 1000000.0 ; printf ("\ntest use time - %02d:%02d:%02d\n\n" , INT (time_use / 3600.0 ), INT (time_use) % 3600 / 60 , INT (time_use) % 60 ); if (!output_model)return ; FILE *fout = fopen ((output_path + "word2vec" + note + ".txt" ).c_str (), "w" ); fprintf (fout, "%d\t%d\n" , word_total, dimension); for (INT i = 0 ; i < word_total; i++) { for (INT j = 0 ; j < dimension; j++) fprintf (fout, "%f\t" , word_vec[i * dimension + j]); fprintf (fout, "\n" ); } fclose (fout); fout = fopen ((output_path + "position_vec" + note + ".txt" ).c_str (), "w" ); fprintf (fout, "%d\t%d\t%d\n" , position_total_head, position_total_tail, dimension_pos); for (INT i = 0 ; i < position_total_head; i++) { for (INT j = 0 ; j < dimension_pos; j++) fprintf (fout, "%f\t" , position_vec_head[i * dimension_pos + j]); fprintf (fout, "\n" ); } for (INT i = 0 ; i < position_total_tail; i++) { for (INT j = 0 ; j < dimension_pos; j++) fprintf (fout, "%f\t" , position_vec_tail[i * dimension_pos + j]); fprintf (fout, "\n" ); } fclose (fout); fout = fopen ((output_path + "conv_1d" + note + ".txt" ).c_str (), "w" ); fprintf (fout,"%d\t%d\t%d\t%d\n" , dimension_c, window, dimension, dimension_pos); for (INT i = 0 ; i < dimension_c; i++) { for (INT j = 0 ; j < window * dimension; j++) fprintf (fout, "%f\t" , conv_1d_word[i * window * dimension + j]); for (INT j = 0 ; j < window * dimension_pos; j++) fprintf (fout, "%f\t" , conv_1d_position_head[i * window * dimension_pos + j]); for (INT j = 0 ; j < window * dimension_pos; j++) fprintf (fout, "%f\t" , conv_1d_position_tail[i * window * dimension_pos + j]); fprintf (fout, "%f\n" , conv_1d_bias[i]); } fclose (fout); fout = fopen ((output_path + "attention_weights" + note + ".txt" ).c_str (), "w" ); fprintf (fout,"%d\t%d\n" , relation_total, dimension_c); for (INT r = 0 ; r < relation_total; r++) { for (INT i_x = 0 ; i_x < dimension_c; i_x++) { for (INT i_r = 0 ; i_r < dimension_c; i_r++) fprintf (fout, "%f\t" , attention_weights[r][i_x][i_r]); fprintf (fout, "\n" ); } } fclose (fout); fout = fopen ((output_path + "relation_matrix" + note + ".txt" ).c_str (), "w" ); fprintf (fout, "%d\t%d\t%f\n" , relation_total, dimension_c, dropout_probability); for (INT i_r = 0 ; i_r < relation_total; i_r++) { for (INT i_s = 0 ; i_s < dimension_c; i_s++) fprintf (fout, "%f\t" , relation_matrix[i_r * dimension_c + i_s]); fprintf (fout, "\n" ); } for (INT i_r = 0 ; i_r < relation_total; i_r++) fprintf (fout, "%f\t" , relation_matrix_bias[i_r]); fprintf (fout, "\n" ); fclose (fout); printf ("模型保存成功, 保存目录为: %s\n\n" , output_path.c_str ()); } #endif
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 269 270 271 272 273 274 275 276 277 278 279 280 281 282 283 284 285 286 287 288 289 290 291 292 293 294 295 296 297 298 299 300 301 302 303 304 305 306 307 308 309 310 311 312 313 314 315 316 317 318 319 320 321 322 323 324 325 326 327 328 329 330 331 332 333 334 335 336 337 338 339 340 341 342 343 344 345 346 347 348 349 350 351 352 353 354 355 356 357 358 359 360 361 362 363 364 365 366 367 368 369 370 371 372 373 374 375 376 377 378 379 380 381 382 383 384 385 386 387 388 389 390 391 392 393 394 395 396 397 398 399 400 401 402 403 404 405 406 407 408 409 410 411 412 413 414 415 416 417 418 419 420 421 422 423 424 425 426 427 428 429 430 431 432 433 434 435 436 437 438 439 440 441 442 443 444 445 446 447 448 449 450 451 452 453 454 455 456 457 458 459 460 461 462 463 464 465 466 467 468 469 470 471 472 473 474 475 476 477 478 479 480 481 482 483 484 485 486 487 488 489 490 491 492 493 494 495 496 497 498 499 500 501 502 503 504 505 506 507 508 509 510 511 512 513 514 515 516 517 518 519 520 521 522 523 524 525 526 527 528 529 530 531 532 533 534 535 536 537 538 539 540 #include "init.h" #include "test.h" std::vector<std::string> bags_train_key; double total_loss = 0 ;REAL current_alpha; double current_sample = 0 , final_sample = 0 ;pthread_mutex_t train_mutex;INT len; INT nbatches; struct timeval train_start, train_end;std::vector<REAL> calc_conv_1d (INT *sentence, INT *train_position_head, INT *train_position_tail, INT sentence_length, std::vector<INT> &max_pool_window_k) std::vector<REAL> conv_1d_result_k; conv_1d_result_k.resize (dimension_c, 0 ); for (INT i = 0 ; i < dimension_c; i++) { INT last_word = i * window * dimension; INT last_pos = i * window * dimension_pos; REAL max_pool_1d = -FLT_MAX; for (INT last_window = 0 ; last_window <= sentence_length - window; last_window++) { REAL sum = 0 ; INT total_word = 0 ; INT total_pos = 0 ; for (INT j = last_window; j < last_window + window; j++) { INT last_word_vec = sentence[j] * dimension; for (INT k = 0 ; k < dimension; k++) { sum += conv_1d_word_copy[last_word + total_word] * word_vec_copy[last_word_vec + k]; total_word++; } INT last_pos_head = train_position_head[j] * dimension_pos; INT last_pos_tail = train_position_tail[j] * dimension_pos; for (INT k = 0 ; k < dimension_pos; k++) { sum += conv_1d_position_head_copy[last_pos + total_pos] * position_vec_head_copy[last_pos_head + k]; sum += conv_1d_position_tail_copy[last_pos + total_pos] * position_vec_tail_copy[last_pos_tail + k]; total_pos++; } } if (sum > max_pool_1d) { max_pool_1d = sum; max_pool_window_k[i] = last_window; } } conv_1d_result_k[i] = max_pool_1d + conv_1d_bias_copy[i]; } for (INT i = 0 ; i < dimension_c; i++) { conv_1d_result_k[i] = calc_tanh (conv_1d_result_k[i]); } return conv_1d_result_k; } void gradient_conv_1d (INT *sentence, INT *train_position_head, INT *train_position_tail, std::vector<REAL> &conv_1d_result_k, std::vector<INT> &max_pool_window_k, std::vector<REAL> &grad_x_k) for (INT i = 0 ; i < dimension_c; i++) { if (fabs (grad_x_k[i]) < 1e-8 ) continue ; INT last_word = i * window * dimension; INT last_pos = i * window * dimension_pos; INT total_word = 0 ; INT total_pos = 0 ; REAL grad_word_pos = grad_x_k[i] * (1 - conv_1d_result_k[i] * conv_1d_result_k[i]); for (INT j = 0 ; j < window; j++) { INT last_word_vec = sentence[max_pool_window_k[i] + j] * dimension; for (INT k = 0 ; k < dimension; k++) { conv_1d_word[last_word + total_word] -= grad_word_pos * word_vec_copy[last_word_vec + k]; word_vec[last_word_vec + k] -= grad_word_pos * conv_1d_word_copy[last_word + total_word]; total_word++; } INT last_pos_head = train_position_head[max_pool_window_k[i] + j] * dimension_pos; INT last_pos_tail = train_position_tail[max_pool_window_k[i] + j] * dimension_pos; for (INT k = 0 ; k < dimension_pos; k++) { conv_1d_position_head[last_pos + total_pos] -= grad_word_pos * position_vec_head_copy[last_pos_head + k]; conv_1d_position_tail[last_pos + total_pos] -= grad_word_pos * position_vec_tail_copy[last_pos_tail + k]; position_vec_head[last_pos_head + k] -= grad_word_pos * conv_1d_position_head_copy[last_pos + total_pos]; position_vec_tail[last_pos_tail + k] -= grad_word_pos * conv_1d_position_tail_copy[last_pos + total_pos]; total_pos++; } } conv_1d_bias[i] -= grad_word_pos; } } REAL train_bags (std::string bags_name) INT relation = -1 ; INT bags_size = bags_train[bags_name].size (); std::vector<std::vector<INT> > max_pool_window; max_pool_window.resize (bags_size); std::vector<std::vector<REAL> > conv_1d_result; for (INT k = 0 ; k < bags_size; k++) { max_pool_window[k].resize (dimension_c); INT pos = bags_train[bags_name][k]; if (relation == -1 ) relation = train_relation_list[pos]; else assert (relation == train_relation_list[pos]); conv_1d_result.push_back (calc_conv_1d (train_sentence_list[pos], train_position_head[pos], train_position_tail[pos], train_length[pos], max_pool_window[k])); } std::vector<REAL> weight; REAL weight_sum = 0 ; for (INT k = 0 ; k < bags_size; k++) { REAL s = 0 ; for (INT i_r = 0 ; i_r < dimension_c; i_r++) { REAL temp = 0 ; for (INT i_x = 0 ; i_x < dimension_c; i_x++) temp += conv_1d_result[k][i_x] * attention_weights_copy[relation][i_x][i_r]; s += temp * relation_matrix_copy[relation * dimension_c + i_r]; } s = exp (s); weight.push_back (s); weight_sum += s; } for (INT k = 0 ; k < bags_size; k++) weight[k] /= weight_sum; std::vector<REAL> result_sentence; result_sentence.resize (dimension_c); for (INT i = 0 ; i < dimension_c; i++) for (INT k = 0 ; k < bags_size; k++) result_sentence[i] += conv_1d_result[k][i] * weight[k]; std::vector<REAL> result_final; std::vector<INT> dropout; for (INT i_s = 0 ; i_s < dimension_c; i_s++) dropout.push_back ((REAL)(rand ()) / (RAND_MAX + 1.0 ) < dropout_probability); REAL sum = 0 ; for (INT i_r = 0 ; i_r < relation_total; i_r++) { REAL s = 0 ; for (INT i_s = 0 ; i_s < dimension_c; i_s++) { s += dropout[i_s] * result_sentence[i_s] * relation_matrix_copy[i_r * dimension_c + i_s]; } s += relation_matrix_bias_copy[i_r]; s = exp (s); sum += s; result_final.push_back (s); } double loss = -(log (result_final[relation]) - log (sum)); std::vector<REAL> grad_s; grad_s.resize (dimension_c); for (INT i_r = 0 ; i_r < relation_total; i_r++) { REAL grad_final = result_final[i_r] / sum * current_alpha; if (i_r == relation) grad_final -= current_alpha; for (INT i_s = 0 ; i_s < dimension_c; i_s++) { REAL grad_i_s = 0 ; if (dropout[i_s] != 0 ) { grad_i_s += grad_final * relation_matrix_copy[i_r * dimension_c + i_s]; relation_matrix[i_r * dimension_c + i_s] -= grad_final * result_sentence[i_s]; } grad_s[i_s] += grad_i_s; } relation_matrix_bias[i_r] -= grad_final; } std::vector<std::vector<REAL> > grad_x; grad_x.resize (bags_size); for (INT k = 0 ; k < bags_size; k++) grad_x[k].resize (dimension_c); for (INT i_r = 0 ; i_r < dimension_c; i_r++) { REAL grad_i_s = grad_s[i_r]; double a_denominator_sum_exp = 0 ; for (INT k = 0 ; k < bags_size; k++) { grad_x[k][i_r] += grad_i_s * weight[k]; for (INT i_x = 0 ; i_x < dimension_c; i_x++) { grad_x[k][i_x] += grad_i_s * conv_1d_result[k][i_r] * weight[k] * relation_matrix_copy[relation * dimension_c + i_r] * attention_weights_copy[relation][i_x][i_r]; relation_matrix[relation * dimension_c + i_r] -= grad_i_s * conv_1d_result[k][i_r] * weight[k] * conv_1d_result[k][i_x] * attention_weights_copy[relation][i_x][i_r]; if (i_r == i_x) attention_weights[relation][i_x][i_r] -= grad_i_s * conv_1d_result[k][i_r] * weight[k] * conv_1d_result[k][i_x] * relation_matrix_copy[relation * dimension_c + i_r]; } a_denominator_sum_exp += conv_1d_result[k][i_r] * weight[k]; } for (INT k = 0 ; k < bags_size; k++) { for (INT i_x = 0 ; i_x < dimension_c; i_x++) { grad_x[k][i_x]-= grad_i_s * a_denominator_sum_exp * weight[k] * relation_matrix_copy[relation * dimension_c + i_r] * attention_weights_copy[relation][i_x][i_r]; relation_matrix[relation * dimension_c + i_r] += grad_i_s * a_denominator_sum_exp * weight[k] * conv_1d_result[k][i_x] * attention_weights_copy[relation][i_x][i_r]; if (i_r == i_x) attention_weights[relation][i_x][i_r] += grad_i_s * a_denominator_sum_exp * weight[k] * conv_1d_result[k][i_x] * relation_matrix_copy[relation * dimension_c + i_r]; } } } for (INT k = 0 ; k < bags_size; k++) { INT pos = bags_train[bags_name][k]; gradient_conv_1d (train_sentence_list[pos], train_position_head[pos], train_position_tail[pos], conv_1d_result[k], max_pool_window[k], grad_x[k]); } return loss; } void * train_mode (void *id) while (true ) { pthread_mutex_lock (&train_mutex); if (current_sample >= final_sample) { pthread_mutex_unlock (&train_mutex); break ; } current_sample += 1 ; pthread_mutex_unlock (&train_mutex); INT i = get_rand_i (0 , len); total_loss += train_bags (bags_train_key[i]); } } void train () len = bags_train.size (); nbatches = len / (batch * num_threads); bags_train_key.clear (); for (std::map<std::string, std::vector<INT> >:: iterator it = bags_train.begin (); it != bags_train.end (); it++) { bags_train_key.push_back (it->first); } position_vec_head = (REAL *)calloc (position_total_head * dimension_pos, sizeof (REAL)); position_vec_tail = (REAL *)calloc (position_total_tail * dimension_pos, sizeof (REAL)); conv_1d_word = (REAL*)calloc (dimension_c * window * dimension, sizeof (REAL)); conv_1d_position_head = (REAL *)calloc (dimension_c * window * dimension_pos, sizeof (REAL)); conv_1d_position_tail = (REAL *)calloc (dimension_c * window * dimension_pos, sizeof (REAL)); conv_1d_bias = (REAL*)calloc (dimension_c, sizeof (REAL)); attention_weights.resize (relation_total); for (INT i = 0 ; i < relation_total; i++) { attention_weights[i].resize (dimension_c); for (INT j = 0 ; j < dimension_c; j++) { attention_weights[i][j].resize (dimension_c); attention_weights[i][j][j] = 1.00 ; } } relation_matrix = (REAL *)calloc (relation_total * dimension_c, sizeof (REAL)); relation_matrix_bias = (REAL *)calloc (relation_total, sizeof (REAL)); word_vec_copy = (REAL *)calloc (dimension * word_total, sizeof (REAL)); position_vec_head_copy = (REAL *)calloc (position_total_head * dimension_pos, sizeof (REAL)); position_vec_tail_copy = (REAL *)calloc (position_total_tail * dimension_pos, sizeof (REAL)); conv_1d_word_copy = (REAL*)calloc (dimension_c * window * dimension, sizeof (REAL)); conv_1d_position_head_copy = (REAL *)calloc (dimension_c * window * dimension_pos, sizeof (REAL)); conv_1d_position_tail_copy = (REAL *)calloc (dimension_c * window * dimension_pos, sizeof (REAL)); conv_1d_bias_copy = (REAL*)calloc (dimension_c, sizeof (REAL)); attention_weights_copy = attention_weights; relation_matrix_copy = (REAL *)calloc (relation_total * dimension_c, sizeof (REAL)); relation_matrix_bias_copy = (REAL *)calloc (relation_total, sizeof (REAL)); REAL relation_matrix_init = sqrt (6.0 / (relation_total + dimension_c)); REAL conv_1d_position_vec_init = sqrt (6.0 / ((dimension + dimension_pos) * window)); for (INT i = 0 ; i < position_total_head; i++) { for (INT j = 0 ; j < dimension_pos; j++) { position_vec_head[i * dimension_pos + j] = get_rand_u (-conv_1d_position_vec_init, conv_1d_position_vec_init); } } for (INT i = 0 ; i < position_total_tail; i++) { for (INT j = 0 ; j < dimension_pos; j++) { position_vec_tail[i * dimension_pos + j] = get_rand_u (-conv_1d_position_vec_init, conv_1d_position_vec_init); } } for (INT i = 0 ; i < dimension_c; i++) { INT last = i * window * dimension; for (INT j = 0 ; j < window * dimension; j++) conv_1d_word[last + j] = get_rand_u (-conv_1d_position_vec_init, conv_1d_position_vec_init); last = i * window * dimension_pos; for (INT j = dimension_pos * window - 1 ; j >=0 ; j--) { conv_1d_position_head[last + j] = get_rand_u (-conv_1d_position_vec_init, conv_1d_position_vec_init); conv_1d_position_tail[last + j] = get_rand_u (-conv_1d_position_vec_init, conv_1d_position_vec_init); } conv_1d_bias[i] = get_rand_u (-conv_1d_position_vec_init, conv_1d_position_vec_init); } for (INT i = 0 ; i < relation_total; i++) { for (INT j = 0 ; j < dimension_c; j++) relation_matrix[i * dimension_c + j] = get_rand_u (-relation_matrix_init, relation_matrix_init); relation_matrix_bias[i] = get_rand_u (-relation_matrix_init, relation_matrix_init); } printf ("##################################################\n\nTrain start...\n\n" ); for (INT epoch = 1 ; epoch <= epochs; epoch++) { current_alpha = alpha * current_rate; current_sample = 0 ; final_sample = 0 ; total_loss = 0 ; gettimeofday (&train_start, NULL ); for (INT i = 1 ; i <= nbatches; i++) { final_sample += batch * num_threads; memcpy (word_vec_copy, word_vec, word_total * dimension * sizeof (REAL)); memcpy (position_vec_head_copy, position_vec_head, position_total_head * dimension_pos * sizeof (REAL)); memcpy (position_vec_tail_copy, position_vec_tail, position_total_tail * dimension_pos * sizeof (REAL)); memcpy (conv_1d_word_copy, conv_1d_word, dimension_c * window * dimension * sizeof (REAL)); memcpy (conv_1d_position_head_copy, conv_1d_position_head, dimension_c * window * dimension_pos * sizeof (REAL)); memcpy (conv_1d_position_tail_copy, conv_1d_position_tail, dimension_c * window * dimension_pos * sizeof (REAL)); memcpy (conv_1d_bias_copy, conv_1d_bias, dimension_c * sizeof (REAL)); attention_weights_copy = attention_weights; memcpy (relation_matrix_copy, relation_matrix, relation_total * dimension_c * sizeof (REAL)); memcpy (relation_matrix_bias_copy, relation_matrix_bias, relation_total * sizeof (REAL)); pthread_t *pt = (pthread_t *)malloc (num_threads * sizeof (pthread_t )); for (long a = 0 ; a < num_threads; a++) pthread_create (&pt[a], NULL , train_mode, (void *)a); for (long a = 0 ; a < num_threads; a++) pthread_join (pt[a], NULL ); free (pt); } gettimeofday (&train_end, NULL ); long double time_use = (1000000 * (train_end.tv_sec - train_start.tv_sec) + train_end.tv_usec - train_start.tv_usec) / 1000000.0 ; printf ("Epoch %d/%d - current_alpha: %.8f - loss: %f - %02d:%02d:%02d\n\n" , epoch, epochs, current_alpha, total_loss / final_sample, INT (time_use / 3600.0 ), INT (time_use) % 3600 / 60 , INT (time_use) % 60 ); test (); printf ("Test end.\n\n##################################################\n\n" ); current_rate = current_rate * reduce_epoch; } printf ("Train end.\n\n##################################################\n\n" ); } void setparameters (INT argc, char **argv) INT i; if ((i = arg_pos ((char *)"-batch" , argc, argv)) > 0 ) batch = atoi (argv[i + 1 ]); if ((i = arg_pos ((char *)"-threads" , argc, argv)) > 0 ) num_threads = atoi (argv[i + 1 ]); if ((i = arg_pos ((char *)"-alpha" , argc, argv)) > 0 ) alpha = atof (argv[i + 1 ]); if ((i = arg_pos ((char *)"-init_rate" , argc, argv)) > 0 ) current_rate = atof (argv[i + 1 ]); if ((i = arg_pos ((char *)"-reduce_epoch" , argc, argv)) > 0 ) reduce_epoch = atof (argv[i + 1 ]); if ((i = arg_pos ((char *)"-epochs" , argc, argv)) > 0 ) epochs = atoi (argv[i + 1 ]); if ((i = arg_pos ((char *)"-limit" , argc, argv)) > 0 ) limit = atoi (argv[i + 1 ]); if ((i = arg_pos ((char *)"-dimension_pos" , argc, argv)) > 0 ) dimension_pos = atoi (argv[i + 1 ]); if ((i = arg_pos ((char *)"-window" , argc, argv)) > 0 ) window = atoi (argv[i + 1 ]); if ((i = arg_pos ((char *)"-dimension_c" , argc, argv)) > 0 ) dimension_c = atoi (argv[i + 1 ]); if ((i = arg_pos ((char *)"-dropout" , argc, argv)) > 0 ) dropout_probability = atof (argv[i + 1 ]); if ((i = arg_pos ((char *)"-output_model" , argc, argv)) > 0 ) output_model = atoi (argv[i + 1 ]); if ((i = arg_pos ((char *)"-note" , argc, argv)) > 0 ) note = argv[i + 1 ]; if ((i = arg_pos ((char *)"-data_path" , argc, argv)) > 0 ) data_path = argv[i + 1 ]; if ((i = arg_pos ((char *)"-output_path" , argc, argv)) > 0 ) output_path = argv[i + 1 ]; } void print_train_help () std::string str = R"( // ################################################## // ./train [-batch BATCH] [-threads THREAD] [-alpha ALPHA] // [-init_rate INIT_RATE] [-reduce_epoch REDUCE_EPOCH] // [-epochs EPOCHS] [-limit LIMIT] [-dimension_pos DIMENSION_POS] // [-window WINDOW] [-dimension_c DIMENSION_C] // [-dropout DROPOUT] [-output_model 0/1] // [-note NOTE] [-data_path DATA_PATH] // [-output_path OUTPUT_PATH] [--help] // optional arguments: // -batch BATCH batch size. if unspecified, batch will default to [40] // -threads THREAD number of worker threads. if unspecified, num_threads will default to [32] // -alpha ALPHA learning rate. if unspecified, alpha will default to [0.00125] // -init_rate INIT_RATE init rate of learning rate. if unspecified, current_rate will default to [1.0] // -reduce_epoch REDUCE_EPOCH reduce of init rate of learning rate per epoch. if unspecified, reduce_epoch will default to [0.98] // -epochs EPOCHS number of epochs. if unspecified, epochs will default to [25] // -limit LIMIT 限制句子中 (头, 尾) 实体相对每个单词的最大距离. 默认值为 [30] // -dimension_pos DIMENSION_POS 位置嵌入维度,默认值为 [5] // -window WINDOW 一维卷积的 window 大小. 默认值为 [3] // -dimension_c DIMENSION_C sentence embedding size, if unspecified, dimension_c will default to [230] // -dropout DROPOUT dropout probability. if unspecified, dropout_probability will default to [0.5] // -output_model 0/1 [1] 保存模型, [0] 不保存模型. 默认值为 [1] // -note NOTE information you want to add to the filename, like ("./output/word2vec" + note + ".txt"). if unspecified, note will default to "" // -data_path DATA_PATH folder of data. if unspecified, data_path will default to "../data/" // -output_path OUTPUT_PATH folder of outputing results (precion/recall curves) and models. if unspecified, output_path will default to "./output/" // --help print help information of ./train // ################################################## )" ; printf ("%s\n" , str.c_str ()); } INT main (INT argc, char **argv) { for (INT a = 1 ; a < argc; a++) if (!strcmp ((char *)"--help" , argv[a])) { print_train_help (); return 0 ; } output_model = 1 ; setparameters (argc, argv); init (); print_information (); train (); return 0 ; }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 #include "init.h" #include "test.h" void load_model () position_vec_head = (REAL *)calloc (position_total_head * dimension_pos, sizeof (REAL)); position_vec_tail = (REAL *)calloc (position_total_tail * dimension_pos, sizeof (REAL)); conv_1d_word = (REAL*)calloc (dimension_c * dimension * window, sizeof (REAL)); conv_1d_position_head = (REAL *)calloc (dimension_c * dimension_pos * window, sizeof (REAL)); conv_1d_position_tail = (REAL *)calloc (dimension_c * dimension_pos * window, sizeof (REAL)); conv_1d_bias = (REAL*)calloc (dimension_c, sizeof (REAL)); attention_weights.resize (relation_total); for (INT i = 0 ; i < relation_total; i++) { attention_weights[i].resize (dimension_c); for (INT j = 0 ; j < dimension_c; j++) attention_weights[i][j].resize (dimension_c); } relation_matrix = (REAL *)calloc (relation_total * dimension_c, sizeof (REAL)); relation_matrix_bias = (REAL *)calloc (relation_total, sizeof (REAL)); INT tmp; FILE *fout = fopen ((output_path + "word2vec" + note + ".txt" ).c_str (), "r" ); tmp = fscanf (fout,"%d%d" , &word_total, &dimension); for (INT i = 0 ; i < word_total; i++) { for (INT j = 0 ; j < dimension; j++) tmp = fscanf (fout, "%f" , &word_vec[i * dimension + j]); } fclose (fout); fout = fopen ((output_path + "position_vec" + note + ".txt" ).c_str (), "r" ); tmp = fscanf (fout, "%d%d%d" , &position_total_head, &position_total_tail, &dimension_pos); for (INT i = 0 ; i < position_total_head; i++) { for (INT j = 0 ; j < dimension_pos; j++) tmp = fscanf (fout, "%f" , &position_vec_head[i * dimension_pos + j]); } for (INT i = 0 ; i < position_total_tail; i++) { for (INT j = 0 ; j < dimension_pos; j++) tmp = fscanf (fout, "%f" , &position_vec_tail[i * dimension_pos + j]); } fclose (fout); fout = fopen ((output_path + "conv_1d" + note + ".txt" ).c_str (), "r" ); tmp = fscanf (fout, "%d%d%d%d" , &dimension_c, &window, &dimension, &dimension_pos); for (INT i = 0 ; i < dimension_c; i++) { for (INT j = 0 ; j < window * dimension; j++) tmp = fscanf (fout, "%f" , &conv_1d_word[i * window * dimension + j]); for (INT j = 0 ; j < window * dimension_pos; j++) tmp = fscanf (fout, "%f" , &conv_1d_position_head[i * window * dimension_pos + j]); for (INT j = 0 ; j < window * dimension_pos; j++) tmp = fscanf (fout, "%f" , &conv_1d_position_tail[i * window * dimension_pos + j]); tmp = fscanf (fout, "%f" , &conv_1d_bias[i]); } fclose (fout); fout = fopen ((output_path + "attention_weights" + note + ".txt" ).c_str (), "r" ); tmp = fscanf (fout,"%d%d" , &relation_total, &dimension_c); for (INT r = 0 ; r < relation_total; r++) { for (INT i_x = 0 ; i_x < dimension_c; i_x++) { for (INT i_r = 0 ; i_r < dimension_c; i_r++) tmp = fscanf (fout, "%f" , &attention_weights[r][i_x][i_r]); } } fclose (fout); fout = fopen ((output_path + "relation_matrix" + note + ".txt" ).c_str (), "r" ); tmp = fscanf (fout, "%d%d%f" , &relation_total, &dimension_c, &dropout_probability); for (INT i_r = 0 ; i_r < relation_total; i_r++) { for (INT i_s = 0 ; i_s < dimension_c; i_s++) tmp = fscanf (fout, "%f" , &relation_matrix[i_r * dimension_c + i_s]); } for (INT i_r = 0 ; i_r < relation_total; i_r++) tmp = fscanf (fout, "%f" , &relation_matrix_bias[i_r]); fclose (fout); printf ("模型加载成功!\n\n" ); } void setparameters (INT argc, char **argv) INT i; if ((i = arg_pos ((char *)"-threads" , argc, argv)) > 0 ) num_threads = atoi (argv[i + 1 ]); if ((i = arg_pos ((char *)"-note" , argc, argv)) > 0 ) note = argv[i + 1 ]; if ((i = arg_pos ((char *)"-data_path" , argc, argv)) > 0 ) data_path = argv[i + 1 ]; if ((i = arg_pos ((char *)"-load_path" , argc, argv)) > 0 ) output_path = argv[i + 1 ]; } void print_test_help () std::string str = R"( // ################################################## // ./test [-threads THREAD] [-dropout DROPOUT] // [-note NOTE] [-data_path DATA_PATH] // [-load_path LOAD_PATH] [--help] // optional arguments: // -threads THREAD number of worker threads. if unspecified, num_threads will default to [32] // -note NOTE information you want to add to the filename, like ("./output/word2vec" + note + ".txt"). if unspecified, note will default to "" // -data_path DATA_PATH folder of data. if unspecified, data_path will default to "../data/" // -load_path LOAD_PATH folder of pretrained models. if unspecified, load_path will default to "./output/" // --help print help information of ./test // ################################################## )" ; printf ("%s\n" , str.c_str ()); } INT main (INT argc, char **argv) { for (INT a = 1 ; a < argc; a++) if (!strcmp ((char *)"--help" , argv[a])) { print_test_help (); return 0 ; } setparameters (argc, argv); init (); load_model (); print_information (); test (); printf ("Test end.\n\n##################################################\n\n" ); return 0 ; }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 #!/bin/bash echo "" echo "##################################################" echo "" mkdir -p buildmkdir -p outputecho "./build 和 ./output 目录创建成功." g++ train.cpp -o ./build/train -pthread -O3 -march=native g++ test.cpp -o ./build/test -pthread -O3 -march=native ./build/train
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 #!/bin/bash echo "" echo "##################################################" echo "" rm -rf ./buildecho "./build 目录递归删除成功." echo "" echo "##################################################" echo ""
使用
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 269 270 271 272 273 274 275 276 277 278 279 280 281 282 283 284 285 286 287 288 289 290 291 292 293 294 295 296 297 298 299 300 301 302 303 304 305 306 307 308 309 310 311 312 313 314 315 316 317 318 319 320 321 322 323 324 325 326 327 328 329 330 331 332 333 334 335 336 337 338 339 340 341 342 343 344 345 346 347 348 349 350 351 352 353 354 355 356 357 358 359 360 361 362 363 364 365 366 367 368 369 370 371 372 373 374 375 376 377 378 379 380 381 382 383 384 385 386 387 388 389 390 391 392 393 394 395 396 397 398 399 400 401 402 403 404 405 406 407 408 409 410 411 412 413 414 415 416 417 418 419 420 421 422 423 424 425 426 427 428 429 430 431 432 433 434 435 436 437 438 439 440 441 442 443 444 445 446 447 448 449 450 451 452 453 454 455 456 457 458 459 460 461 462 463 464 465 466 467 468 469 470 471 472 473 474 475 476 477 478 479 480 481 482 483 484 485 486 487 488 489 490 491 492 493 494 495 496 497 498 499 500 501 502 503 504 505 506 507 508 509 510 511 512 513 514 515 516 517 518 519 520 521 522 523 524 525 526 527 528 529 530 531 532 533 534 535 536 537 538 539 540 541 542 543 544 545 546 547 548 549 550 551 552 553 554 555 556 557 558 559 560 561 562 563 564 565 566 567 568 569 570 571 572 573 574 575 576 577 578 579 580 581 582 583 584 585 586 587 588 589 590 591 592 593 594 595 596 597 598 599 600 601 602 603 604 605 606 607 608 609 610 611 612 613 614 615 616 617 618 619 620 621 622 623 624 625 626 627 628 629 630 631 632 633 634 635 636 637 638 639 640 641 642 643 644 645 646 647 648 649 650 651 652 653 654 655 656 657 658 659 660 661 662 663 664 665 666 667 668 669 670 671 672 673 674 675 676 677 678 679 680 681 682 683 684 685 686 687 688 689 690 691 692 693 694 695 696 697 698 699 700 701 702 703 704 705 706 707 708 709 710 711 712 713 714 715 716 717 718 719 720 721 722 723 724 725 726 727 728 729 730 731 732 733 734 735 736 737 738 739 740 741 742 743 744 745 746 747 748 749 750 751 752 753 754 755 756 757 758 759 760 761 762 763 764 765 766 767 768 769 770 771 772 773 774 775 776 777 778 779 780 781 782 783 784 785 786 787 788 789 790 791 792 793 794 795 796 797 798 799 800 801 802 803 804 805 806 807 808 809 810 811 812 813 814 815 816 817 818 819 820 821 822 823 824 825 826 827 828 829 830 831 832 833 834 835 836 837 838 839 840 841 842 843 844 845 846 847 848 849 850 851 852 853 854 855 856 857 858 859 860 861 862 863 864 865 866 867 868 869 870 871 872 873 874 875 876 877 878 879 880 881 882 883 884 885 886 887 888 889 890 891 892 893 894 895 896 897 898 899 900 901 902 903 904 905 906 907 908 909 910 911 912 913 914 915 916 917 918 919 920 921 922 923 924 925 926 927 928 929 930 931 932 933 934 935 936 937 938 939 940 941 942 943 944 945 946 947 948 949 950 951 952 953 954 955 956 957 958 959 960 961 962 963 964 965 966 967 968 969 970 971 972 973 974 975 976 977 978 979 980 981 982 983 984 985 986 987 988 989 990 991 992 993 994 995 996 997 998 999 1000 1001 1002 1003 1004 1005 1006 1007 1008 1009 1010 1011 1012 1013 1014 1015 1016 1017 1018 1019 1020 1021 1022 1023 1024 1025 1026 1027 1028 1029 1030 1031 1032 1033 1034 1035 1036 1037 1038 1039 1040 1041 1042 1043 1044 1045 1046 1047 1048 1049 1050 1051 1052 1053 1054 1055 1056 1057 1058 1059 1060 1061 1062 1063 1064 1065 1066 1067 1068 1069 1070 1071 1072 1073 1074 1075 1076 1077 1078 1079 1080 1081 1082 1083 1084 1085 1086 1087 1088 1089 1090 1091 1092 1093 1094 1095 1096 1097 1098 1099 1100 1101 1102 1103 1104 1105 1106 1107 1108 1109 1110 1111 1112 1113 1114 1115 1116 1117 1118 1119 1120 1121 1122 1123 1124 1125 1126 1127 1128 1129 1130 1131 1132 1133 1134 1135 1136 1137 1138 1139 1140 1141 1142 1143 1144 1145 1146 1147 1148 1149 1150 1151 1152 1153 1154 1155 1156 1157 1158 1159 1160 1161 1162 1163 1164 1165 1166 1167 1168 1169 1170 1171 1172 1173 1174 1175 1176 1177 1178 1179 1180 1181 1182 1183 1184 1185 1186 1187 1188 1189 1190 1191 1192 1193 1194 1195 1196 1197 1198 1199 1200 1201 1202 1203 1204 1205 1206 1207 1208 1209 1210 1211 1212 1213 1214 1215 1216 1217 1218 1219 1220 1221 1222 1223 1224 1225 1226 1227 1228 1229 1230 1231 1232 1233 1234 1235 1236 1237 1238 1239 1240 1241 1242 1243 1244 1245 1246 1247 1248 1249 1250 1251 1252 1253 1254 1255 1256 1257 1258 1259 1260 1261 1262 1263 1264 1265 1266 1267 1268 1269 1270 1271 1272 1273 1274 1275 1276 1277 1278 1279 1280 1281 1282 1283 1284 1285 1286 1287 1288 1289 1290 1291 1292 1293 1294 1295 1296 1297 1298 1299 1300 1301 1302 1303 1304 1305 1306 1307 1308 1309 1310 1311 1312 1313 1314 1315 1316 1317 1318 1319 1320 1321 1322 1323 1324 1325 1326 1327 1328 1329 1330 1331 1332 1333 1334 1335 1336 1337 1338 1339 1340 1341 1342 1343 1344 1345 1346 1347 1348 1349 1350 1351 1352 1353 1354 1355 1356 1357 1358 1359 1360 1361 1362 1363 1364 1365 1366 1367 1368 1369 1370 1371 1372 1373 1374 1375 1376 1377 1378 1379 1380 1381 1382 1383 1384 1385 1386 1387 1388 1389 1390 1391 1392 1393 1394 1395 1396 1397 1398 1399 1400 1401 1402 1403 1404 1405 1406 1407 1408 1409 1410 1411 1412 1413 1414 1415 1416 1417 1418 1419 1420 1421 1422 1423 1424 1425 1426 1427 1428 1429 1430 1431 1432 1433 1434 1435 1436 1437 1438 1439 1440 1441 1442 1443 1444 1445 1446 1447 1448 1449 1450 1451 1452 1453 1454 1455 1456 1457 1458 1459 1460 1461 1462 1463 1464 1465 1466 1467 1468 1469 1470 1471 1472 1473 1474 1475 1476 1477 1478 1479 1480 1481 1482 1483 1484 1485 1486 1487 1488 1489 1490 1491 1492 1493 1494 1495 1496 1497 1498 1499 1500 1501 1502 1503 1504 1505 1506 1507 1508 1509 1510 1511 1512 1513 1514 1515 1516 1517 1518 1519 1520 1521 1522 1523 1524 1525 $ ls clean.sh init.h run.sh test.cpp test.h train.cpp $ bash run.sh # ./build 和 ./output 目录创建成功. # Init start... 训练数据和测试数据加载成功! batch: 40 number of threads: 32 learning rate: 0.00125000 init_rate: 1.00 reduce_epoch: 0.98 epochs: 25 word_total: 114043 word dimension: 50 limit: 30 position_total_head: 61 position_total_tail: 61 dimension_pos: 5 window: 3 dimension_c: 230 relation_total: 53 dropout_probability: 0.50 将会保存模型. note: folder of data: ../data/ folder of outputing results (precion/recall curves) and models: ./output/ number of training samples: 281270 - average sentence number of per training sample: 1.86 number of testing samples: 96678 - average sentence number of per testing sample: 1.78 Init end. # Train start... Epoch 1/25 - current_alpha: 0.00125000 - loss: 0.392392 - 00:04:00 # Test start... Number of test samples for non NA relation: 1950 precion/recall curves 50 / 2000 - precision: 0.280 - recall: 0.007 precion/recall curves 100 / 2000 - precision: 0.210 - recall: 0.011 precion/recall curves 150 / 2000 - precision: 0.187 - recall: 0.014 precion/recall curves 200 / 2000 - precision: 0.185 - recall: 0.019 precion/recall curves 250 / 2000 - precision: 0.164 - recall: 0.021 precion/recall curves 300 / 2000 - precision: 0.147 - recall: 0.023 precion/recall curves 350 / 2000 - precision: 0.134 - recall: 0.024 precion/recall curves 400 / 2000 - precision: 0.125 - recall: 0.026 precion/recall curves 450 / 2000 - precision: 0.120 - recall: 0.028 precion/recall curves 500 / 2000 - precision: 0.122 - recall: 0.031 precion/recall curves 550 / 2000 - precision: 0.125 - recall: 0.035 precion/recall curves 600 / 2000 - precision: 0.118 - recall: 0.036 precion/recall curves 650 / 2000 - precision: 0.118 - recall: 0.039 precion/recall curves 700 / 2000 - precision: 0.116 - recall: 0.042 precion/recall curves 750 / 2000 - precision: 0.109 - recall: 0.042 precion/recall curves 800 / 2000 - precision: 0.109 - recall: 0.045 precion/recall curves 850 / 2000 - precision: 0.105 - recall: 0.046 precion/recall curves 900 / 2000 - precision: 0.104 - recall: 0.048 precion/recall curves 950 / 2000 - precision: 0.102 - recall: 0.050 precion/recall curves 1000 / 2000 - precision: 0.101 - recall: 0.052 precion/recall curves 1050 / 2000 - precision: 0.102 - recall: 0.055 precion/recall curves 1100 / 2000 - precision: 0.099 - recall: 0.056 precion/recall curves 1150 / 2000 - precision: 0.097 - recall: 0.057 precion/recall curves 1200 / 2000 - precision: 0.094 - recall: 0.058 precion/recall curves 1250 / 2000 - precision: 0.092 - recall: 0.059 precion/recall curves 1300 / 2000 - precision: 0.090 - recall: 0.060 precion/recall curves 1350 / 2000 - precision: 0.087 - recall: 0.061 precion/recall curves 1400 / 2000 - precision: 0.085 - recall: 0.061 precion/recall curves 1450 / 2000 - precision: 0.083 - recall: 0.062 precion/recall curves 1500 / 2000 - precision: 0.085 - recall: 0.065 precion/recall curves 1550 / 2000 - precision: 0.084 - recall: 0.067 precion/recall curves 1600 / 2000 - precision: 0.083 - recall: 0.068 precion/recall curves 1650 / 2000 - precision: 0.082 - recall: 0.069 precion/recall curves 1700 / 2000 - precision: 0.081 - recall: 0.071 precion/recall curves 1750 / 2000 - precision: 0.081 - recall: 0.073 precion/recall curves 1800 / 2000 - precision: 0.081 - recall: 0.075 precion/recall curves 1850 / 2000 - precision: 0.082 - recall: 0.078 precion/recall curves 1900 / 2000 - precision: 0.080 - recall: 0.078 precion/recall curves 1950 / 2000 - precision: 0.080 - recall: 0.080 precion/recall curves 2000 / 2000 - precision: 0.079 - recall: 0.081 test use time - 00:01:21 模型保存成功, 保存目录为: ./output/ Test end. # Epoch 2/25 - current_alpha: 0.00122500 - loss: 0.312926 - 00:04:58 # Test start... Number of test samples for non NA relation: 1950 precion/recall curves 50 / 2000 - precision: 0.560 - recall: 0.014 precion/recall curves 100 / 2000 - precision: 0.540 - recall: 0.028 precion/recall curves 150 / 2000 - precision: 0.573 - recall: 0.044 precion/recall curves 200 / 2000 - precision: 0.555 - recall: 0.057 precion/recall curves 250 / 2000 - precision: 0.536 - recall: 0.069 precion/recall curves 300 / 2000 - precision: 0.517 - recall: 0.079 precion/recall curves 350 / 2000 - precision: 0.483 - recall: 0.087 precion/recall curves 400 / 2000 - precision: 0.468 - recall: 0.096 precion/recall curves 450 / 2000 - precision: 0.433 - recall: 0.100 precion/recall curves 500 / 2000 - precision: 0.412 - recall: 0.106 precion/recall curves 550 / 2000 - precision: 0.404 - recall: 0.114 precion/recall curves 600 / 2000 - precision: 0.388 - recall: 0.119 precion/recall curves 650 / 2000 - precision: 0.375 - recall: 0.125 precion/recall curves 700 / 2000 - precision: 0.370 - recall: 0.133 precion/recall curves 750 / 2000 - precision: 0.359 - recall: 0.138 precion/recall curves 800 / 2000 - precision: 0.350 - recall: 0.144 precion/recall curves 850 / 2000 - precision: 0.339 - recall: 0.148 precion/recall curves 900 / 2000 - precision: 0.332 - recall: 0.153 precion/recall curves 950 / 2000 - precision: 0.322 - recall: 0.157 precion/recall curves 1000 / 2000 - precision: 0.312 - recall: 0.160 precion/recall curves 1050 / 2000 - precision: 0.304 - recall: 0.164 precion/recall curves 1100 / 2000 - precision: 0.294 - recall: 0.166 precion/recall curves 1150 / 2000 - precision: 0.285 - recall: 0.168 precion/recall curves 1200 / 2000 - precision: 0.279 - recall: 0.172 precion/recall curves 1250 / 2000 - precision: 0.277 - recall: 0.177 precion/recall curves 1300 / 2000 - precision: 0.271 - recall: 0.181 precion/recall curves 1350 / 2000 - precision: 0.264 - recall: 0.183 precion/recall curves 1400 / 2000 - precision: 0.256 - recall: 0.184 precion/recall curves 1450 / 2000 - precision: 0.253 - recall: 0.188 precion/recall curves 1500 / 2000 - precision: 0.249 - recall: 0.191 precion/recall curves 1550 / 2000 - precision: 0.245 - recall: 0.194 precion/recall curves 1600 / 2000 - precision: 0.238 - recall: 0.195 precion/recall curves 1650 / 2000 - precision: 0.233 - recall: 0.197 precion/recall curves 1700 / 2000 - precision: 0.228 - recall: 0.198 precion/recall curves 1750 / 2000 - precision: 0.225 - recall: 0.202 precion/recall curves 1800 / 2000 - precision: 0.220 - recall: 0.203 precion/recall curves 1850 / 2000 - precision: 0.216 - recall: 0.205 precion/recall curves 1900 / 2000 - precision: 0.212 - recall: 0.207 precion/recall curves 1950 / 2000 - precision: 0.208 - recall: 0.208 precion/recall curves 2000 / 2000 - precision: 0.204 - recall: 0.209 test use time - 00:01:22 模型保存成功, 保存目录为: ./output/ Test end. # Epoch 3/25 - current_alpha: 0.00120050 - loss: 0.263319 - 00:04:04 # Test start... Number of test samples for non NA relation: 1950 precion/recall curves 50 / 2000 - precision: 0.500 - recall: 0.013 precion/recall curves 100 / 2000 - precision: 0.550 - recall: 0.028 precion/recall curves 150 / 2000 - precision: 0.560 - recall: 0.043 precion/recall curves 200 / 2000 - precision: 0.585 - recall: 0.060 precion/recall curves 250 / 2000 - precision: 0.556 - recall: 0.071 precion/recall curves 300 / 2000 - precision: 0.527 - recall: 0.081 precion/recall curves 350 / 2000 - precision: 0.506 - recall: 0.091 precion/recall curves 400 / 2000 - precision: 0.490 - recall: 0.101 precion/recall curves 450 / 2000 - precision: 0.460 - recall: 0.106 precion/recall curves 500 / 2000 - precision: 0.448 - recall: 0.115 precion/recall curves 550 / 2000 - precision: 0.433 - recall: 0.122 precion/recall curves 600 / 2000 - precision: 0.420 - recall: 0.129 precion/recall curves 650 / 2000 - precision: 0.405 - recall: 0.135 precion/recall curves 700 / 2000 - precision: 0.394 - recall: 0.142 precion/recall curves 750 / 2000 - precision: 0.379 - recall: 0.146 precion/recall curves 800 / 2000 - precision: 0.371 - recall: 0.152 precion/recall curves 850 / 2000 - precision: 0.362 - recall: 0.158 precion/recall curves 900 / 2000 - precision: 0.353 - recall: 0.163 precion/recall curves 950 / 2000 - precision: 0.348 - recall: 0.170 precion/recall curves 1000 / 2000 - precision: 0.340 - recall: 0.174 precion/recall curves 1050 / 2000 - precision: 0.330 - recall: 0.177 precion/recall curves 1100 / 2000 - precision: 0.325 - recall: 0.183 precion/recall curves 1150 / 2000 - precision: 0.319 - recall: 0.188 precion/recall curves 1200 / 2000 - precision: 0.313 - recall: 0.193 precion/recall curves 1250 / 2000 - precision: 0.307 - recall: 0.197 precion/recall curves 1300 / 2000 - precision: 0.302 - recall: 0.201 precion/recall curves 1350 / 2000 - precision: 0.295 - recall: 0.204 precion/recall curves 1400 / 2000 - precision: 0.288 - recall: 0.207 precion/recall curves 1450 / 2000 - precision: 0.283 - recall: 0.211 precion/recall curves 1500 / 2000 - precision: 0.277 - recall: 0.213 precion/recall curves 1550 / 2000 - precision: 0.270 - recall: 0.214 precion/recall curves 1600 / 2000 - precision: 0.262 - recall: 0.215 precion/recall curves 1650 / 2000 - precision: 0.258 - recall: 0.218 precion/recall curves 1700 / 2000 - precision: 0.255 - recall: 0.223 precion/recall curves 1750 / 2000 - precision: 0.251 - recall: 0.225 precion/recall curves 1800 / 2000 - precision: 0.248 - recall: 0.229 precion/recall curves 1850 / 2000 - precision: 0.243 - recall: 0.230 precion/recall curves 1900 / 2000 - precision: 0.239 - recall: 0.233 precion/recall curves 1950 / 2000 - precision: 0.235 - recall: 0.235 precion/recall curves 2000 / 2000 - precision: 0.231 - recall: 0.237 test use time - 00:01:21 模型保存成功, 保存目录为: ./output/ Test end. # Epoch 4/25 - current_alpha: 0.00117649 - loss: 0.234492 - 00:03:50 # Test start... Number of test samples for non NA relation: 1950 precion/recall curves 50 / 2000 - precision: 0.600 - recall: 0.015 precion/recall curves 100 / 2000 - precision: 0.600 - recall: 0.031 precion/recall curves 150 / 2000 - precision: 0.600 - recall: 0.046 precion/recall curves 200 / 2000 - precision: 0.590 - recall: 0.061 precion/recall curves 250 / 2000 - precision: 0.560 - recall: 0.072 precion/recall curves 300 / 2000 - precision: 0.540 - recall: 0.083 precion/recall curves 350 / 2000 - precision: 0.534 - recall: 0.096 precion/recall curves 400 / 2000 - precision: 0.507 - recall: 0.104 precion/recall curves 450 / 2000 - precision: 0.484 - recall: 0.112 precion/recall curves 500 / 2000 - precision: 0.480 - recall: 0.123 precion/recall curves 550 / 2000 - precision: 0.475 - recall: 0.134 precion/recall curves 600 / 2000 - precision: 0.470 - recall: 0.145 precion/recall curves 650 / 2000 - precision: 0.457 - recall: 0.152 precion/recall curves 700 / 2000 - precision: 0.451 - recall: 0.162 precion/recall curves 750 / 2000 - precision: 0.443 - recall: 0.170 precion/recall curves 800 / 2000 - precision: 0.438 - recall: 0.179 precion/recall curves 850 / 2000 - precision: 0.431 - recall: 0.188 precion/recall curves 900 / 2000 - precision: 0.416 - recall: 0.192 precion/recall curves 950 / 2000 - precision: 0.407 - recall: 0.198 precion/recall curves 1000 / 2000 - precision: 0.401 - recall: 0.206 precion/recall curves 1050 / 2000 - precision: 0.399 - recall: 0.215 precion/recall curves 1100 / 2000 - precision: 0.391 - recall: 0.221 precion/recall curves 1150 / 2000 - precision: 0.384 - recall: 0.227 precion/recall curves 1200 / 2000 - precision: 0.376 - recall: 0.231 precion/recall curves 1250 / 2000 - precision: 0.369 - recall: 0.236 precion/recall curves 1300 / 2000 - precision: 0.366 - recall: 0.244 precion/recall curves 1350 / 2000 - precision: 0.361 - recall: 0.250 precion/recall curves 1400 / 2000 - precision: 0.356 - recall: 0.256 precion/recall curves 1450 / 2000 - precision: 0.350 - recall: 0.260 precion/recall curves 1500 / 2000 - precision: 0.341 - recall: 0.263 precion/recall curves 1550 / 2000 - precision: 0.336 - recall: 0.267 precion/recall curves 1600 / 2000 - precision: 0.333 - recall: 0.273 precion/recall curves 1650 / 2000 - precision: 0.327 - recall: 0.277 precion/recall curves 1700 / 2000 - precision: 0.321 - recall: 0.279 precion/recall curves 1750 / 2000 - precision: 0.314 - recall: 0.282 precion/recall curves 1800 / 2000 - precision: 0.310 - recall: 0.286 precion/recall curves 1850 / 2000 - precision: 0.306 - recall: 0.290 precion/recall curves 1900 / 2000 - precision: 0.302 - recall: 0.294 precion/recall curves 1950 / 2000 - precision: 0.298 - recall: 0.298 precion/recall curves 2000 / 2000 - precision: 0.294 - recall: 0.301 test use time - 00:01:21 模型保存成功, 保存目录为: ./output/ Test end. # Epoch 5/25 - current_alpha: 0.00115296 - loss: 0.211013 - 00:03:39 # Test start... Number of test samples for non NA relation: 1950 precion/recall curves 50 / 2000 - precision: 0.600 - recall: 0.015 precion/recall curves 100 / 2000 - precision: 0.600 - recall: 0.031 precion/recall curves 150 / 2000 - precision: 0.600 - recall: 0.046 precion/recall curves 200 / 2000 - precision: 0.590 - recall: 0.061 precion/recall curves 250 / 2000 - precision: 0.580 - recall: 0.074 precion/recall curves 300 / 2000 - precision: 0.560 - recall: 0.086 precion/recall curves 350 / 2000 - precision: 0.569 - recall: 0.102 precion/recall curves 400 / 2000 - precision: 0.562 - recall: 0.115 precion/recall curves 450 / 2000 - precision: 0.538 - recall: 0.124 precion/recall curves 500 / 2000 - precision: 0.530 - recall: 0.136 precion/recall curves 550 / 2000 - precision: 0.522 - recall: 0.147 precion/recall curves 600 / 2000 - precision: 0.512 - recall: 0.157 precion/recall curves 650 / 2000 - precision: 0.497 - recall: 0.166 precion/recall curves 700 / 2000 - precision: 0.487 - recall: 0.175 precion/recall curves 750 / 2000 - precision: 0.477 - recall: 0.184 precion/recall curves 800 / 2000 - precision: 0.466 - recall: 0.191 precion/recall curves 850 / 2000 - precision: 0.449 - recall: 0.196 precion/recall curves 900 / 2000 - precision: 0.443 - recall: 0.205 precion/recall curves 950 / 2000 - precision: 0.438 - recall: 0.213 precion/recall curves 1000 / 2000 - precision: 0.438 - recall: 0.225 precion/recall curves 1050 / 2000 - precision: 0.428 - recall: 0.230 precion/recall curves 1100 / 2000 - precision: 0.418 - recall: 0.236 precion/recall curves 1150 / 2000 - precision: 0.410 - recall: 0.242 precion/recall curves 1200 / 2000 - precision: 0.404 - recall: 0.249 precion/recall curves 1250 / 2000 - precision: 0.399 - recall: 0.256 precion/recall curves 1300 / 2000 - precision: 0.392 - recall: 0.262 precion/recall curves 1350 / 2000 - precision: 0.386 - recall: 0.267 precion/recall curves 1400 / 2000 - precision: 0.377 - recall: 0.271 precion/recall curves 1450 / 2000 - precision: 0.371 - recall: 0.276 precion/recall curves 1500 / 2000 - precision: 0.367 - recall: 0.283 precion/recall curves 1550 / 2000 - precision: 0.360 - recall: 0.286 precion/recall curves 1600 / 2000 - precision: 0.357 - recall: 0.293 precion/recall curves 1650 / 2000 - precision: 0.351 - recall: 0.297 precion/recall curves 1700 / 2000 - precision: 0.344 - recall: 0.300 precion/recall curves 1750 / 2000 - precision: 0.340 - recall: 0.305 precion/recall curves 1800 / 2000 - precision: 0.335 - recall: 0.309 precion/recall curves 1850 / 2000 - precision: 0.329 - recall: 0.312 precion/recall curves 1900 / 2000 - precision: 0.325 - recall: 0.317 precion/recall curves 1950 / 2000 - precision: 0.323 - recall: 0.323 precion/recall curves 2000 / 2000 - precision: 0.317 - recall: 0.325 test use time - 00:01:23 模型保存成功, 保存目录为: ./output/ Test end. # Epoch 6/25 - current_alpha: 0.00112990 - loss: 0.201362 - 00:04:17 # Test start... Number of test samples for non NA relation: 1950 precion/recall curves 50 / 2000 - precision: 0.660 - recall: 0.017 precion/recall curves 100 / 2000 - precision: 0.620 - recall: 0.032 precion/recall curves 150 / 2000 - precision: 0.600 - recall: 0.046 precion/recall curves 200 / 2000 - precision: 0.610 - recall: 0.063 precion/recall curves 250 / 2000 - precision: 0.592 - recall: 0.076 precion/recall curves 300 / 2000 - precision: 0.563 - recall: 0.087 precion/recall curves 350 / 2000 - precision: 0.560 - recall: 0.101 precion/recall curves 400 / 2000 - precision: 0.567 - recall: 0.116 precion/recall curves 450 / 2000 - precision: 0.560 - recall: 0.129 precion/recall curves 500 / 2000 - precision: 0.552 - recall: 0.142 precion/recall curves 550 / 2000 - precision: 0.540 - recall: 0.152 precion/recall curves 600 / 2000 - precision: 0.528 - recall: 0.163 precion/recall curves 650 / 2000 - precision: 0.515 - recall: 0.172 precion/recall curves 700 / 2000 - precision: 0.504 - recall: 0.181 precion/recall curves 750 / 2000 - precision: 0.496 - recall: 0.191 precion/recall curves 800 / 2000 - precision: 0.485 - recall: 0.199 precion/recall curves 850 / 2000 - precision: 0.472 - recall: 0.206 precion/recall curves 900 / 2000 - precision: 0.463 - recall: 0.214 precion/recall curves 950 / 2000 - precision: 0.452 - recall: 0.220 precion/recall curves 1000 / 2000 - precision: 0.447 - recall: 0.229 precion/recall curves 1050 / 2000 - precision: 0.438 - recall: 0.236 precion/recall curves 1100 / 2000 - precision: 0.432 - recall: 0.244 precion/recall curves 1150 / 2000 - precision: 0.427 - recall: 0.252 precion/recall curves 1200 / 2000 - precision: 0.421 - recall: 0.259 precion/recall curves 1250 / 2000 - precision: 0.418 - recall: 0.268 precion/recall curves 1300 / 2000 - precision: 0.412 - recall: 0.274 precion/recall curves 1350 / 2000 - precision: 0.405 - recall: 0.281 precion/recall curves 1400 / 2000 - precision: 0.398 - recall: 0.286 precion/recall curves 1450 / 2000 - precision: 0.391 - recall: 0.291 precion/recall curves 1500 / 2000 - precision: 0.385 - recall: 0.296 precion/recall curves 1550 / 2000 - precision: 0.379 - recall: 0.302 precion/recall curves 1600 / 2000 - precision: 0.373 - recall: 0.306 precion/recall curves 1650 / 2000 - precision: 0.369 - recall: 0.312 precion/recall curves 1700 / 2000 - precision: 0.361 - recall: 0.315 precion/recall curves 1750 / 2000 - precision: 0.355 - recall: 0.319 precion/recall curves 1800 / 2000 - precision: 0.351 - recall: 0.324 precion/recall curves 1850 / 2000 - precision: 0.345 - recall: 0.327 precion/recall curves 1900 / 2000 - precision: 0.342 - recall: 0.333 precion/recall curves 1950 / 2000 - precision: 0.337 - recall: 0.337 precion/recall curves 2000 / 2000 - precision: 0.331 - recall: 0.339 test use time - 00:01:22 模型保存成功, 保存目录为: ./output/ Test end. # Epoch 7/25 - current_alpha: 0.00110730 - loss: 0.189826 - 00:03:58 # Test start... Number of test samples for non NA relation: 1950 precion/recall curves 50 / 2000 - precision: 0.640 - recall: 0.016 precion/recall curves 100 / 2000 - precision: 0.620 - recall: 0.032 precion/recall curves 150 / 2000 - precision: 0.627 - recall: 0.048 precion/recall curves 200 / 2000 - precision: 0.595 - recall: 0.061 precion/recall curves 250 / 2000 - precision: 0.592 - recall: 0.076 precion/recall curves 300 / 2000 - precision: 0.577 - recall: 0.089 precion/recall curves 350 / 2000 - precision: 0.560 - recall: 0.101 precion/recall curves 400 / 2000 - precision: 0.565 - recall: 0.116 precion/recall curves 450 / 2000 - precision: 0.576 - recall: 0.133 precion/recall curves 500 / 2000 - precision: 0.560 - recall: 0.144 precion/recall curves 550 / 2000 - precision: 0.562 - recall: 0.158 precion/recall curves 600 / 2000 - precision: 0.543 - recall: 0.167 precion/recall curves 650 / 2000 - precision: 0.525 - recall: 0.175 precion/recall curves 700 / 2000 - precision: 0.520 - recall: 0.187 precion/recall curves 750 / 2000 - precision: 0.515 - recall: 0.198 precion/recall curves 800 / 2000 - precision: 0.500 - recall: 0.205 precion/recall curves 850 / 2000 - precision: 0.495 - recall: 0.216 precion/recall curves 900 / 2000 - precision: 0.481 - recall: 0.222 precion/recall curves 950 / 2000 - precision: 0.482 - recall: 0.235 precion/recall curves 1000 / 2000 - precision: 0.473 - recall: 0.243 precion/recall curves 1050 / 2000 - precision: 0.470 - recall: 0.253 precion/recall curves 1100 / 2000 - precision: 0.462 - recall: 0.261 precion/recall curves 1150 / 2000 - precision: 0.452 - recall: 0.267 precion/recall curves 1200 / 2000 - precision: 0.442 - recall: 0.272 precion/recall curves 1250 / 2000 - precision: 0.436 - recall: 0.279 precion/recall curves 1300 / 2000 - precision: 0.424 - recall: 0.283 precion/recall curves 1350 / 2000 - precision: 0.413 - recall: 0.286 precion/recall curves 1400 / 2000 - precision: 0.404 - recall: 0.290 precion/recall curves 1450 / 2000 - precision: 0.401 - recall: 0.298 precion/recall curves 1500 / 2000 - precision: 0.392 - recall: 0.302 precion/recall curves 1550 / 2000 - precision: 0.389 - recall: 0.309 precion/recall curves 1600 / 2000 - precision: 0.381 - recall: 0.312 precion/recall curves 1650 / 2000 - precision: 0.374 - recall: 0.316 precion/recall curves 1700 / 2000 - precision: 0.370 - recall: 0.323 precion/recall curves 1750 / 2000 - precision: 0.370 - recall: 0.332 precion/recall curves 1800 / 2000 - precision: 0.366 - recall: 0.338 precion/recall curves 1850 / 2000 - precision: 0.362 - recall: 0.343 precion/recall curves 1900 / 2000 - precision: 0.356 - recall: 0.347 precion/recall curves 1950 / 2000 - precision: 0.351 - recall: 0.351 precion/recall curves 2000 / 2000 - precision: 0.345 - recall: 0.354 test use time - 00:01:21 模型保存成功, 保存目录为: ./output/ Test end. # Epoch 8/25 - current_alpha: 0.00108516 - loss: 0.182470 - 00:03:33 # Test start... Number of test samples for non NA relation: 1950 precion/recall curves 50 / 2000 - precision: 0.680 - recall: 0.017 precion/recall curves 100 / 2000 - precision: 0.650 - recall: 0.033 precion/recall curves 150 / 2000 - precision: 0.633 - recall: 0.049 precion/recall curves 200 / 2000 - precision: 0.620 - recall: 0.064 precion/recall curves 250 / 2000 - precision: 0.616 - recall: 0.079 precion/recall curves 300 / 2000 - precision: 0.597 - recall: 0.092 precion/recall curves 350 / 2000 - precision: 0.614 - recall: 0.110 precion/recall curves 400 / 2000 - precision: 0.615 - recall: 0.126 precion/recall curves 450 / 2000 - precision: 0.607 - recall: 0.140 precion/recall curves 500 / 2000 - precision: 0.602 - recall: 0.154 precion/recall curves 550 / 2000 - precision: 0.589 - recall: 0.166 precion/recall curves 600 / 2000 - precision: 0.570 - recall: 0.175 precion/recall curves 650 / 2000 - precision: 0.557 - recall: 0.186 precion/recall curves 700 / 2000 - precision: 0.547 - recall: 0.196 precion/recall curves 750 / 2000 - precision: 0.536 - recall: 0.206 precion/recall curves 800 / 2000 - precision: 0.525 - recall: 0.215 precion/recall curves 850 / 2000 - precision: 0.516 - recall: 0.225 precion/recall curves 900 / 2000 - precision: 0.507 - recall: 0.234 precion/recall curves 950 / 2000 - precision: 0.495 - recall: 0.241 precion/recall curves 1000 / 2000 - precision: 0.484 - recall: 0.248 precion/recall curves 1050 / 2000 - precision: 0.472 - recall: 0.254 precion/recall curves 1100 / 2000 - precision: 0.467 - recall: 0.264 precion/recall curves 1150 / 2000 - precision: 0.463 - recall: 0.273 precion/recall curves 1200 / 2000 - precision: 0.454 - recall: 0.279 precion/recall curves 1250 / 2000 - precision: 0.450 - recall: 0.288 precion/recall curves 1300 / 2000 - precision: 0.440 - recall: 0.293 precion/recall curves 1350 / 2000 - precision: 0.431 - recall: 0.298 precion/recall curves 1400 / 2000 - precision: 0.424 - recall: 0.305 precion/recall curves 1450 / 2000 - precision: 0.419 - recall: 0.311 precion/recall curves 1500 / 2000 - precision: 0.412 - recall: 0.317 precion/recall curves 1550 / 2000 - precision: 0.406 - recall: 0.323 precion/recall curves 1600 / 2000 - precision: 0.399 - recall: 0.328 precion/recall curves 1650 / 2000 - precision: 0.396 - recall: 0.335 precion/recall curves 1700 / 2000 - precision: 0.390 - recall: 0.340 precion/recall curves 1750 / 2000 - precision: 0.382 - recall: 0.343 precion/recall curves 1800 / 2000 - precision: 0.377 - recall: 0.348 precion/recall curves 1850 / 2000 - precision: 0.375 - recall: 0.355 precion/recall curves 1900 / 2000 - precision: 0.368 - recall: 0.359 precion/recall curves 1950 / 2000 - precision: 0.364 - recall: 0.364 precion/recall curves 2000 / 2000 - precision: 0.356 - recall: 0.366 test use time - 00:01:22 模型保存成功, 保存目录为: ./output/ Test end. # Epoch 9/25 - current_alpha: 0.00106345 - loss: 0.174141 - 00:03:59 # Test start... Number of test samples for non NA relation: 1950 precion/recall curves 50 / 2000 - precision: 0.780 - recall: 0.020 precion/recall curves 100 / 2000 - precision: 0.650 - recall: 0.033 precion/recall curves 150 / 2000 - precision: 0.613 - recall: 0.047 precion/recall curves 200 / 2000 - precision: 0.600 - recall: 0.062 precion/recall curves 250 / 2000 - precision: 0.616 - recall: 0.079 precion/recall curves 300 / 2000 - precision: 0.607 - recall: 0.093 precion/recall curves 350 / 2000 - precision: 0.600 - recall: 0.108 precion/recall curves 400 / 2000 - precision: 0.605 - recall: 0.124 precion/recall curves 450 / 2000 - precision: 0.609 - recall: 0.141 precion/recall curves 500 / 2000 - precision: 0.578 - recall: 0.148 precion/recall curves 550 / 2000 - precision: 0.575 - recall: 0.162 precion/recall curves 600 / 2000 - precision: 0.565 - recall: 0.174 precion/recall curves 650 / 2000 - precision: 0.562 - recall: 0.187 precion/recall curves 700 / 2000 - precision: 0.553 - recall: 0.198 precion/recall curves 750 / 2000 - precision: 0.537 - recall: 0.207 precion/recall curves 800 / 2000 - precision: 0.520 - recall: 0.213 precion/recall curves 850 / 2000 - precision: 0.507 - recall: 0.221 precion/recall curves 900 / 2000 - precision: 0.500 - recall: 0.231 precion/recall curves 950 / 2000 - precision: 0.492 - recall: 0.239 precion/recall curves 1000 / 2000 - precision: 0.483 - recall: 0.248 precion/recall curves 1050 / 2000 - precision: 0.471 - recall: 0.254 precion/recall curves 1100 / 2000 - precision: 0.462 - recall: 0.261 precion/recall curves 1150 / 2000 - precision: 0.460 - recall: 0.271 precion/recall curves 1200 / 2000 - precision: 0.452 - recall: 0.278 precion/recall curves 1250 / 2000 - precision: 0.443 - recall: 0.284 precion/recall curves 1300 / 2000 - precision: 0.439 - recall: 0.293 precion/recall curves 1350 / 2000 - precision: 0.435 - recall: 0.301 precion/recall curves 1400 / 2000 - precision: 0.429 - recall: 0.308 precion/recall curves 1450 / 2000 - precision: 0.426 - recall: 0.316 precion/recall curves 1500 / 2000 - precision: 0.420 - recall: 0.323 precion/recall curves 1550 / 2000 - precision: 0.414 - recall: 0.329 precion/recall curves 1600 / 2000 - precision: 0.407 - recall: 0.334 precion/recall curves 1650 / 2000 - precision: 0.400 - recall: 0.338 precion/recall curves 1700 / 2000 - precision: 0.395 - recall: 0.345 precion/recall curves 1750 / 2000 - precision: 0.391 - recall: 0.351 precion/recall curves 1800 / 2000 - precision: 0.384 - recall: 0.355 precion/recall curves 1850 / 2000 - precision: 0.378 - recall: 0.359 precion/recall curves 1900 / 2000 - precision: 0.373 - recall: 0.364 precion/recall curves 1950 / 2000 - precision: 0.367 - recall: 0.367 precion/recall curves 2000 / 2000 - precision: 0.361 - recall: 0.371 test use time - 00:01:22 模型保存成功, 保存目录为: ./output/ Test end. # Epoch 10/25 - current_alpha: 0.00104219 - loss: 0.170107 - 00:03:58 # Test start... Number of test samples for non NA relation: 1950 precion/recall curves 50 / 2000 - precision: 0.820 - recall: 0.021 precion/recall curves 100 / 2000 - precision: 0.700 - recall: 0.036 precion/recall curves 150 / 2000 - precision: 0.707 - recall: 0.054 precion/recall curves 200 / 2000 - precision: 0.700 - recall: 0.072 precion/recall curves 250 / 2000 - precision: 0.664 - recall: 0.085 precion/recall curves 300 / 2000 - precision: 0.647 - recall: 0.099 precion/recall curves 350 / 2000 - precision: 0.631 - recall: 0.113 precion/recall curves 400 / 2000 - precision: 0.630 - recall: 0.129 precion/recall curves 450 / 2000 - precision: 0.611 - recall: 0.141 precion/recall curves 500 / 2000 - precision: 0.606 - recall: 0.155 precion/recall curves 550 / 2000 - precision: 0.585 - recall: 0.165 precion/recall curves 600 / 2000 - precision: 0.575 - recall: 0.177 precion/recall curves 650 / 2000 - precision: 0.565 - recall: 0.188 precion/recall curves 700 / 2000 - precision: 0.554 - recall: 0.199 precion/recall curves 750 / 2000 - precision: 0.547 - recall: 0.210 precion/recall curves 800 / 2000 - precision: 0.533 - recall: 0.218 precion/recall curves 850 / 2000 - precision: 0.526 - recall: 0.229 precion/recall curves 900 / 2000 - precision: 0.516 - recall: 0.238 precion/recall curves 950 / 2000 - precision: 0.506 - recall: 0.247 precion/recall curves 1000 / 2000 - precision: 0.497 - recall: 0.255 precion/recall curves 1050 / 2000 - precision: 0.486 - recall: 0.262 precion/recall curves 1100 / 2000 - precision: 0.476 - recall: 0.269 precion/recall curves 1150 / 2000 - precision: 0.472 - recall: 0.278 precion/recall curves 1200 / 2000 - precision: 0.463 - recall: 0.285 precion/recall curves 1250 / 2000 - precision: 0.454 - recall: 0.291 precion/recall curves 1300 / 2000 - precision: 0.444 - recall: 0.296 precion/recall curves 1350 / 2000 - precision: 0.438 - recall: 0.303 precion/recall curves 1400 / 2000 - precision: 0.428 - recall: 0.307 precion/recall curves 1450 / 2000 - precision: 0.426 - recall: 0.316 precion/recall curves 1500 / 2000 - precision: 0.417 - recall: 0.321 precion/recall curves 1550 / 2000 - precision: 0.409 - recall: 0.325 precion/recall curves 1600 / 2000 - precision: 0.403 - recall: 0.331 precion/recall curves 1650 / 2000 - precision: 0.398 - recall: 0.337 precion/recall curves 1700 / 2000 - precision: 0.392 - recall: 0.342 precion/recall curves 1750 / 2000 - precision: 0.387 - recall: 0.348 precion/recall curves 1800 / 2000 - precision: 0.384 - recall: 0.354 precion/recall curves 1850 / 2000 - precision: 0.379 - recall: 0.359 precion/recall curves 1900 / 2000 - precision: 0.372 - recall: 0.363 precion/recall curves 1950 / 2000 - precision: 0.367 - recall: 0.367 precion/recall curves 2000 / 2000 - precision: 0.363 - recall: 0.372 test use time - 00:01:22 模型保存成功, 保存目录为: ./output/ Test end. # Epoch 11/25 - current_alpha: 0.00102134 - loss: 0.164617 - 00:04:04 # Test start... Number of test samples for non NA relation: 1950 precion/recall curves 50 / 2000 - precision: 0.780 - recall: 0.020 precion/recall curves 100 / 2000 - precision: 0.680 - recall: 0.035 precion/recall curves 150 / 2000 - precision: 0.647 - recall: 0.050 precion/recall curves 200 / 2000 - precision: 0.635 - recall: 0.065 precion/recall curves 250 / 2000 - precision: 0.620 - recall: 0.079 precion/recall curves 300 / 2000 - precision: 0.627 - recall: 0.096 precion/recall curves 350 / 2000 - precision: 0.609 - recall: 0.109 precion/recall curves 400 / 2000 - precision: 0.600 - recall: 0.123 precion/recall curves 450 / 2000 - precision: 0.596 - recall: 0.137 precion/recall curves 500 / 2000 - precision: 0.580 - recall: 0.149 precion/recall curves 550 / 2000 - precision: 0.575 - recall: 0.162 precion/recall curves 600 / 2000 - precision: 0.577 - recall: 0.177 precion/recall curves 650 / 2000 - precision: 0.566 - recall: 0.189 precion/recall curves 700 / 2000 - precision: 0.557 - recall: 0.200 precion/recall curves 750 / 2000 - precision: 0.543 - recall: 0.209 precion/recall curves 800 / 2000 - precision: 0.535 - recall: 0.219 precion/recall curves 850 / 2000 - precision: 0.528 - recall: 0.230 precion/recall curves 900 / 2000 - precision: 0.520 - recall: 0.240 precion/recall curves 950 / 2000 - precision: 0.508 - recall: 0.248 precion/recall curves 1000 / 2000 - precision: 0.499 - recall: 0.256 precion/recall curves 1050 / 2000 - precision: 0.491 - recall: 0.265 precion/recall curves 1100 / 2000 - precision: 0.478 - recall: 0.270 precion/recall curves 1150 / 2000 - precision: 0.470 - recall: 0.277 precion/recall curves 1200 / 2000 - precision: 0.461 - recall: 0.284 precion/recall curves 1250 / 2000 - precision: 0.452 - recall: 0.290 precion/recall curves 1300 / 2000 - precision: 0.445 - recall: 0.297 precion/recall curves 1350 / 2000 - precision: 0.436 - recall: 0.302 precion/recall curves 1400 / 2000 - precision: 0.432 - recall: 0.310 precion/recall curves 1450 / 2000 - precision: 0.430 - recall: 0.319 precion/recall curves 1500 / 2000 - precision: 0.429 - recall: 0.330 precion/recall curves 1550 / 2000 - precision: 0.420 - recall: 0.334 precion/recall curves 1600 / 2000 - precision: 0.412 - recall: 0.338 precion/recall curves 1650 / 2000 - precision: 0.406 - recall: 0.344 precion/recall curves 1700 / 2000 - precision: 0.402 - recall: 0.350 precion/recall curves 1750 / 2000 - precision: 0.397 - recall: 0.356 precion/recall curves 1800 / 2000 - precision: 0.391 - recall: 0.361 precion/recall curves 1850 / 2000 - precision: 0.385 - recall: 0.366 precion/recall curves 1900 / 2000 - precision: 0.382 - recall: 0.372 precion/recall curves 1950 / 2000 - precision: 0.375 - recall: 0.375 precion/recall curves 2000 / 2000 - precision: 0.371 - recall: 0.381 test use time - 00:01:22 模型保存成功, 保存目录为: ./output/ Test end. # Epoch 12/25 - current_alpha: 0.00100091 - loss: 0.158291 - 00:03:49 # Test start... Number of test samples for non NA relation: 1950 precion/recall curves 50 / 2000 - precision: 0.760 - recall: 0.019 precion/recall curves 100 / 2000 - precision: 0.680 - recall: 0.035 precion/recall curves 150 / 2000 - precision: 0.653 - recall: 0.050 precion/recall curves 200 / 2000 - precision: 0.640 - recall: 0.066 precion/recall curves 250 / 2000 - precision: 0.636 - recall: 0.082 precion/recall curves 300 / 2000 - precision: 0.623 - recall: 0.096 precion/recall curves 350 / 2000 - precision: 0.609 - recall: 0.109 precion/recall curves 400 / 2000 - precision: 0.595 - recall: 0.122 precion/recall curves 450 / 2000 - precision: 0.587 - recall: 0.135 precion/recall curves 500 / 2000 - precision: 0.576 - recall: 0.148 precion/recall curves 550 / 2000 - precision: 0.571 - recall: 0.161 precion/recall curves 600 / 2000 - precision: 0.562 - recall: 0.173 precion/recall curves 650 / 2000 - precision: 0.557 - recall: 0.186 precion/recall curves 700 / 2000 - precision: 0.550 - recall: 0.197 precion/recall curves 750 / 2000 - precision: 0.547 - recall: 0.210 precion/recall curves 800 / 2000 - precision: 0.538 - recall: 0.221 precion/recall curves 850 / 2000 - precision: 0.534 - recall: 0.233 precion/recall curves 900 / 2000 - precision: 0.521 - recall: 0.241 precion/recall curves 950 / 2000 - precision: 0.517 - recall: 0.252 precion/recall curves 1000 / 2000 - precision: 0.501 - recall: 0.257 precion/recall curves 1050 / 2000 - precision: 0.495 - recall: 0.267 precion/recall curves 1100 / 2000 - precision: 0.482 - recall: 0.272 precion/recall curves 1150 / 2000 - precision: 0.473 - recall: 0.279 precion/recall curves 1200 / 2000 - precision: 0.467 - recall: 0.287 precion/recall curves 1250 / 2000 - precision: 0.460 - recall: 0.295 precion/recall curves 1300 / 2000 - precision: 0.451 - recall: 0.301 precion/recall curves 1350 / 2000 - precision: 0.440 - recall: 0.305 precion/recall curves 1400 / 2000 - precision: 0.434 - recall: 0.311 precion/recall curves 1450 / 2000 - precision: 0.425 - recall: 0.316 precion/recall curves 1500 / 2000 - precision: 0.419 - recall: 0.323 precion/recall curves 1550 / 2000 - precision: 0.412 - recall: 0.328 precion/recall curves 1600 / 2000 - precision: 0.409 - recall: 0.335 precion/recall curves 1650 / 2000 - precision: 0.402 - recall: 0.341 precion/recall curves 1700 / 2000 - precision: 0.396 - recall: 0.345 precion/recall curves 1750 / 2000 - precision: 0.393 - recall: 0.353 precion/recall curves 1800 / 2000 - precision: 0.389 - recall: 0.359 precion/recall curves 1850 / 2000 - precision: 0.384 - recall: 0.364 precion/recall curves 1900 / 2000 - precision: 0.378 - recall: 0.369 precion/recall curves 1950 / 2000 - precision: 0.377 - recall: 0.377 precion/recall curves 2000 / 2000 - precision: 0.371 - recall: 0.381 test use time - 00:01:22 模型保存成功, 保存目录为: ./output/ Test end. # Epoch 13/25 - current_alpha: 0.00098090 - loss: 0.157852 - 00:04:22 # Test start... Number of test samples for non NA relation: 1950 precion/recall curves 50 / 2000 - precision: 0.760 - recall: 0.019 precion/recall curves 100 / 2000 - precision: 0.690 - recall: 0.035 precion/recall curves 150 / 2000 - precision: 0.680 - recall: 0.052 precion/recall curves 200 / 2000 - precision: 0.665 - recall: 0.068 precion/recall curves 250 / 2000 - precision: 0.652 - recall: 0.084 precion/recall curves 300 / 2000 - precision: 0.613 - recall: 0.094 precion/recall curves 350 / 2000 - precision: 0.609 - recall: 0.109 precion/recall curves 400 / 2000 - precision: 0.600 - recall: 0.123 precion/recall curves 450 / 2000 - precision: 0.584 - recall: 0.135 precion/recall curves 500 / 2000 - precision: 0.592 - recall: 0.152 precion/recall curves 550 / 2000 - precision: 0.582 - recall: 0.164 precion/recall curves 600 / 2000 - precision: 0.572 - recall: 0.176 precion/recall curves 650 / 2000 - precision: 0.569 - recall: 0.190 precion/recall curves 700 / 2000 - precision: 0.570 - recall: 0.205 precion/recall curves 750 / 2000 - precision: 0.564 - recall: 0.217 precion/recall curves 800 / 2000 - precision: 0.555 - recall: 0.228 precion/recall curves 850 / 2000 - precision: 0.541 - recall: 0.236 precion/recall curves 900 / 2000 - precision: 0.530 - recall: 0.245 precion/recall curves 950 / 2000 - precision: 0.520 - recall: 0.253 precion/recall curves 1000 / 2000 - precision: 0.507 - recall: 0.260 precion/recall curves 1050 / 2000 - precision: 0.494 - recall: 0.266 precion/recall curves 1100 / 2000 - precision: 0.489 - recall: 0.276 precion/recall curves 1150 / 2000 - precision: 0.482 - recall: 0.284 precion/recall curves 1200 / 2000 - precision: 0.477 - recall: 0.293 precion/recall curves 1250 / 2000 - precision: 0.470 - recall: 0.302 precion/recall curves 1300 / 2000 - precision: 0.461 - recall: 0.307 precion/recall curves 1350 / 2000 - precision: 0.451 - recall: 0.312 precion/recall curves 1400 / 2000 - precision: 0.444 - recall: 0.319 precion/recall curves 1450 / 2000 - precision: 0.438 - recall: 0.326 precion/recall curves 1500 / 2000 - precision: 0.435 - recall: 0.334 precion/recall curves 1550 / 2000 - precision: 0.425 - recall: 0.337 precion/recall curves 1600 / 2000 - precision: 0.416 - recall: 0.342 precion/recall curves 1650 / 2000 - precision: 0.411 - recall: 0.348 precion/recall curves 1700 / 2000 - precision: 0.405 - recall: 0.353 precion/recall curves 1750 / 2000 - precision: 0.397 - recall: 0.356 precion/recall curves 1800 / 2000 - precision: 0.392 - recall: 0.362 precion/recall curves 1850 / 2000 - precision: 0.387 - recall: 0.367 precion/recall curves 1900 / 2000 - precision: 0.383 - recall: 0.373 precion/recall curves 1950 / 2000 - precision: 0.377 - recall: 0.377 precion/recall curves 2000 / 2000 - precision: 0.374 - recall: 0.384 test use time - 00:01:22 模型保存成功, 保存目录为: ./output/ Test end. # Epoch 14/25 - current_alpha: 0.00096128 - loss: 0.153716 - 00:03:42 # Test start... Number of test samples for non NA relation: 1950 precion/recall curves 50 / 2000 - precision: 0.720 - recall: 0.018 precion/recall curves 100 / 2000 - precision: 0.710 - recall: 0.036 precion/recall curves 150 / 2000 - precision: 0.687 - recall: 0.053 precion/recall curves 200 / 2000 - precision: 0.675 - recall: 0.069 precion/recall curves 250 / 2000 - precision: 0.640 - recall: 0.082 precion/recall curves 300 / 2000 - precision: 0.620 - recall: 0.095 precion/recall curves 350 / 2000 - precision: 0.600 - recall: 0.108 precion/recall curves 400 / 2000 - precision: 0.600 - recall: 0.123 precion/recall curves 450 / 2000 - precision: 0.591 - recall: 0.136 precion/recall curves 500 / 2000 - precision: 0.582 - recall: 0.149 precion/recall curves 550 / 2000 - precision: 0.573 - recall: 0.162 precion/recall curves 600 / 2000 - precision: 0.565 - recall: 0.174 precion/recall curves 650 / 2000 - precision: 0.560 - recall: 0.187 precion/recall curves 700 / 2000 - precision: 0.561 - recall: 0.202 precion/recall curves 750 / 2000 - precision: 0.551 - recall: 0.212 precion/recall curves 800 / 2000 - precision: 0.545 - recall: 0.224 precion/recall curves 850 / 2000 - precision: 0.533 - recall: 0.232 precion/recall curves 900 / 2000 - precision: 0.521 - recall: 0.241 precion/recall curves 950 / 2000 - precision: 0.512 - recall: 0.249 precion/recall curves 1000 / 2000 - precision: 0.507 - recall: 0.260 precion/recall curves 1050 / 2000 - precision: 0.495 - recall: 0.267 precion/recall curves 1100 / 2000 - precision: 0.492 - recall: 0.277 precion/recall curves 1150 / 2000 - precision: 0.487 - recall: 0.287 precion/recall curves 1200 / 2000 - precision: 0.477 - recall: 0.293 precion/recall curves 1250 / 2000 - precision: 0.470 - recall: 0.301 precion/recall curves 1300 / 2000 - precision: 0.458 - recall: 0.306 precion/recall curves 1350 / 2000 - precision: 0.456 - recall: 0.315 precion/recall curves 1400 / 2000 - precision: 0.449 - recall: 0.322 precion/recall curves 1450 / 2000 - precision: 0.439 - recall: 0.326 precion/recall curves 1500 / 2000 - precision: 0.431 - recall: 0.332 precion/recall curves 1550 / 2000 - precision: 0.425 - recall: 0.337 precion/recall curves 1600 / 2000 - precision: 0.417 - recall: 0.343 precion/recall curves 1650 / 2000 - precision: 0.412 - recall: 0.349 precion/recall curves 1700 / 2000 - precision: 0.406 - recall: 0.354 precion/recall curves 1750 / 2000 - precision: 0.401 - recall: 0.360 precion/recall curves 1800 / 2000 - precision: 0.396 - recall: 0.366 precion/recall curves 1850 / 2000 - precision: 0.391 - recall: 0.371 precion/recall curves 1900 / 2000 - precision: 0.389 - recall: 0.379 precion/recall curves 1950 / 2000 - precision: 0.381 - recall: 0.381 precion/recall curves 2000 / 2000 - precision: 0.376 - recall: 0.386 test use time - 00:01:22 模型保存成功, 保存目录为: ./output/ Test end. # Epoch 15/25 - current_alpha: 0.00094205 - loss: 0.150468 - 00:04:12 # Test start... Number of test samples for non NA relation: 1950 precion/recall curves 50 / 2000 - precision: 0.780 - recall: 0.020 precion/recall curves 100 / 2000 - precision: 0.710 - recall: 0.036 precion/recall curves 150 / 2000 - precision: 0.693 - recall: 0.053 precion/recall curves 200 / 2000 - precision: 0.675 - recall: 0.069 precion/recall curves 250 / 2000 - precision: 0.688 - recall: 0.088 precion/recall curves 300 / 2000 - precision: 0.653 - recall: 0.101 precion/recall curves 350 / 2000 - precision: 0.629 - recall: 0.113 precion/recall curves 400 / 2000 - precision: 0.598 - recall: 0.123 precion/recall curves 450 / 2000 - precision: 0.582 - recall: 0.134 precion/recall curves 500 / 2000 - precision: 0.580 - recall: 0.149 precion/recall curves 550 / 2000 - precision: 0.576 - recall: 0.163 precion/recall curves 600 / 2000 - precision: 0.570 - recall: 0.175 precion/recall curves 650 / 2000 - precision: 0.555 - recall: 0.185 precion/recall curves 700 / 2000 - precision: 0.544 - recall: 0.195 precion/recall curves 750 / 2000 - precision: 0.536 - recall: 0.206 precion/recall curves 800 / 2000 - precision: 0.530 - recall: 0.217 precion/recall curves 850 / 2000 - precision: 0.524 - recall: 0.228 precion/recall curves 900 / 2000 - precision: 0.519 - recall: 0.239 precion/recall curves 950 / 2000 - precision: 0.512 - recall: 0.249 precion/recall curves 1000 / 2000 - precision: 0.504 - recall: 0.258 precion/recall curves 1050 / 2000 - precision: 0.494 - recall: 0.266 precion/recall curves 1100 / 2000 - precision: 0.488 - recall: 0.275 precion/recall curves 1150 / 2000 - precision: 0.485 - recall: 0.286 precion/recall curves 1200 / 2000 - precision: 0.478 - recall: 0.294 precion/recall curves 1250 / 2000 - precision: 0.470 - recall: 0.301 precion/recall curves 1300 / 2000 - precision: 0.459 - recall: 0.306 precion/recall curves 1350 / 2000 - precision: 0.450 - recall: 0.312 precion/recall curves 1400 / 2000 - precision: 0.441 - recall: 0.316 precion/recall curves 1450 / 2000 - precision: 0.434 - recall: 0.323 precion/recall curves 1500 / 2000 - precision: 0.424 - recall: 0.326 precion/recall curves 1550 / 2000 - precision: 0.421 - recall: 0.334 precion/recall curves 1600 / 2000 - precision: 0.414 - recall: 0.339 precion/recall curves 1650 / 2000 - precision: 0.412 - recall: 0.348 precion/recall curves 1700 / 2000 - precision: 0.407 - recall: 0.355 precion/recall curves 1750 / 2000 - precision: 0.401 - recall: 0.359 precion/recall curves 1800 / 2000 - precision: 0.395 - recall: 0.365 precion/recall curves 1850 / 2000 - precision: 0.390 - recall: 0.370 precion/recall curves 1900 / 2000 - precision: 0.385 - recall: 0.375 precion/recall curves 1950 / 2000 - precision: 0.379 - recall: 0.379 precion/recall curves 2000 / 2000 - precision: 0.377 - recall: 0.386 test use time - 00:01:22 模型保存成功, 保存目录为: ./output/ Test end. # Epoch 16/25 - current_alpha: 0.00092321 - loss: 0.145180 - 00:04:06 # Test start... Number of test samples for non NA relation: 1950 precion/recall curves 50 / 2000 - precision: 0.700 - recall: 0.018 precion/recall curves 100 / 2000 - precision: 0.750 - recall: 0.038 precion/recall curves 150 / 2000 - precision: 0.713 - recall: 0.055 precion/recall curves 200 / 2000 - precision: 0.700 - recall: 0.072 precion/recall curves 250 / 2000 - precision: 0.668 - recall: 0.086 precion/recall curves 300 / 2000 - precision: 0.640 - recall: 0.098 precion/recall curves 350 / 2000 - precision: 0.626 - recall: 0.112 precion/recall curves 400 / 2000 - precision: 0.615 - recall: 0.126 precion/recall curves 450 / 2000 - precision: 0.600 - recall: 0.138 precion/recall curves 500 / 2000 - precision: 0.584 - recall: 0.150 precion/recall curves 550 / 2000 - precision: 0.575 - recall: 0.162 precion/recall curves 600 / 2000 - precision: 0.562 - recall: 0.173 precion/recall curves 650 / 2000 - precision: 0.549 - recall: 0.183 precion/recall curves 700 / 2000 - precision: 0.546 - recall: 0.196 precion/recall curves 750 / 2000 - precision: 0.543 - recall: 0.209 precion/recall curves 800 / 2000 - precision: 0.533 - recall: 0.218 precion/recall curves 850 / 2000 - precision: 0.532 - recall: 0.232 precion/recall curves 900 / 2000 - precision: 0.519 - recall: 0.239 precion/recall curves 950 / 2000 - precision: 0.512 - recall: 0.249 precion/recall curves 1000 / 2000 - precision: 0.507 - recall: 0.260 precion/recall curves 1050 / 2000 - precision: 0.498 - recall: 0.268 precion/recall curves 1100 / 2000 - precision: 0.494 - recall: 0.278 precion/recall curves 1150 / 2000 - precision: 0.484 - recall: 0.286 precion/recall curves 1200 / 2000 - precision: 0.477 - recall: 0.294 precion/recall curves 1250 / 2000 - precision: 0.469 - recall: 0.301 precion/recall curves 1300 / 2000 - precision: 0.464 - recall: 0.309 precion/recall curves 1350 / 2000 - precision: 0.456 - recall: 0.315 precion/recall curves 1400 / 2000 - precision: 0.449 - recall: 0.323 precion/recall curves 1450 / 2000 - precision: 0.443 - recall: 0.329 precion/recall curves 1500 / 2000 - precision: 0.438 - recall: 0.337 precion/recall curves 1550 / 2000 - precision: 0.428 - recall: 0.341 precion/recall curves 1600 / 2000 - precision: 0.424 - recall: 0.348 precion/recall curves 1650 / 2000 - precision: 0.416 - recall: 0.352 precion/recall curves 1700 / 2000 - precision: 0.409 - recall: 0.357 precion/recall curves 1750 / 2000 - precision: 0.403 - recall: 0.362 precion/recall curves 1800 / 2000 - precision: 0.400 - recall: 0.369 precion/recall curves 1850 / 2000 - precision: 0.395 - recall: 0.374 precion/recall curves 1900 / 2000 - precision: 0.391 - recall: 0.381 precion/recall curves 1950 / 2000 - precision: 0.387 - recall: 0.387 precion/recall curves 2000 / 2000 - precision: 0.380 - recall: 0.389 test use time - 00:01:22 模型保存成功, 保存目录为: ./output/ Test end. # Epoch 17/25 - current_alpha: 0.00090475 - loss: 0.142947 - 00:03:53 # Test start... Number of test samples for non NA relation: 1950 precion/recall curves 50 / 2000 - precision: 0.840 - recall: 0.022 precion/recall curves 100 / 2000 - precision: 0.760 - recall: 0.039 precion/recall curves 150 / 2000 - precision: 0.720 - recall: 0.055 precion/recall curves 200 / 2000 - precision: 0.710 - recall: 0.073 precion/recall curves 250 / 2000 - precision: 0.672 - recall: 0.086 precion/recall curves 300 / 2000 - precision: 0.647 - recall: 0.099 precion/recall curves 350 / 2000 - precision: 0.634 - recall: 0.114 precion/recall curves 400 / 2000 - precision: 0.625 - recall: 0.128 precion/recall curves 450 / 2000 - precision: 0.613 - recall: 0.142 precion/recall curves 500 / 2000 - precision: 0.600 - recall: 0.154 precion/recall curves 550 / 2000 - precision: 0.593 - recall: 0.167 precion/recall curves 600 / 2000 - precision: 0.580 - recall: 0.178 precion/recall curves 650 / 2000 - precision: 0.571 - recall: 0.190 precion/recall curves 700 / 2000 - precision: 0.560 - recall: 0.201 precion/recall curves 750 / 2000 - precision: 0.559 - recall: 0.215 precion/recall curves 800 / 2000 - precision: 0.550 - recall: 0.226 precion/recall curves 850 / 2000 - precision: 0.544 - recall: 0.237 precion/recall curves 900 / 2000 - precision: 0.538 - recall: 0.248 precion/recall curves 950 / 2000 - precision: 0.528 - recall: 0.257 precion/recall curves 1000 / 2000 - precision: 0.517 - recall: 0.265 precion/recall curves 1050 / 2000 - precision: 0.503 - recall: 0.271 precion/recall curves 1100 / 2000 - precision: 0.495 - recall: 0.279 precion/recall curves 1150 / 2000 - precision: 0.491 - recall: 0.290 precion/recall curves 1200 / 2000 - precision: 0.484 - recall: 0.298 precion/recall curves 1250 / 2000 - precision: 0.477 - recall: 0.306 precion/recall curves 1300 / 2000 - precision: 0.465 - recall: 0.310 precion/recall curves 1350 / 2000 - precision: 0.457 - recall: 0.316 precion/recall curves 1400 / 2000 - precision: 0.451 - recall: 0.324 precion/recall curves 1450 / 2000 - precision: 0.443 - recall: 0.329 precion/recall curves 1500 / 2000 - precision: 0.438 - recall: 0.337 precion/recall curves 1550 / 2000 - precision: 0.432 - recall: 0.344 precion/recall curves 1600 / 2000 - precision: 0.427 - recall: 0.350 precion/recall curves 1650 / 2000 - precision: 0.420 - recall: 0.355 precion/recall curves 1700 / 2000 - precision: 0.414 - recall: 0.361 precion/recall curves 1750 / 2000 - precision: 0.411 - recall: 0.369 precion/recall curves 1800 / 2000 - precision: 0.405 - recall: 0.374 precion/recall curves 1850 / 2000 - precision: 0.398 - recall: 0.378 precion/recall curves 1900 / 2000 - precision: 0.392 - recall: 0.382 precion/recall curves 1950 / 2000 - precision: 0.388 - recall: 0.388 precion/recall curves 2000 / 2000 - precision: 0.380 - recall: 0.390 test use time - 00:01:22 模型保存成功, 保存目录为: ./output/ Test end. # Epoch 18/25 - current_alpha: 0.00088665 - loss: 0.138729 - 00:03:56 # Test start... Number of test samples for non NA relation: 1950 precion/recall curves 50 / 2000 - precision: 0.800 - recall: 0.021 precion/recall curves 100 / 2000 - precision: 0.780 - recall: 0.040 precion/recall curves 150 / 2000 - precision: 0.727 - recall: 0.056 precion/recall curves 200 / 2000 - precision: 0.695 - recall: 0.071 precion/recall curves 250 / 2000 - precision: 0.676 - recall: 0.087 precion/recall curves 300 / 2000 - precision: 0.643 - recall: 0.099 precion/recall curves 350 / 2000 - precision: 0.620 - recall: 0.111 precion/recall curves 400 / 2000 - precision: 0.615 - recall: 0.126 precion/recall curves 450 / 2000 - precision: 0.613 - recall: 0.142 precion/recall curves 500 / 2000 - precision: 0.612 - recall: 0.157 precion/recall curves 550 / 2000 - precision: 0.605 - recall: 0.171 precion/recall curves 600 / 2000 - precision: 0.588 - recall: 0.181 precion/recall curves 650 / 2000 - precision: 0.577 - recall: 0.192 precion/recall curves 700 / 2000 - precision: 0.567 - recall: 0.204 precion/recall curves 750 / 2000 - precision: 0.553 - recall: 0.213 precion/recall curves 800 / 2000 - precision: 0.543 - recall: 0.223 precion/recall curves 850 / 2000 - precision: 0.533 - recall: 0.232 precion/recall curves 900 / 2000 - precision: 0.521 - recall: 0.241 precion/recall curves 950 / 2000 - precision: 0.518 - recall: 0.252 precion/recall curves 1000 / 2000 - precision: 0.511 - recall: 0.262 precion/recall curves 1050 / 2000 - precision: 0.506 - recall: 0.272 precion/recall curves 1100 / 2000 - precision: 0.502 - recall: 0.283 precion/recall curves 1150 / 2000 - precision: 0.490 - recall: 0.289 precion/recall curves 1200 / 2000 - precision: 0.477 - recall: 0.293 precion/recall curves 1250 / 2000 - precision: 0.469 - recall: 0.301 precion/recall curves 1300 / 2000 - precision: 0.463 - recall: 0.309 precion/recall curves 1350 / 2000 - precision: 0.453 - recall: 0.314 precion/recall curves 1400 / 2000 - precision: 0.449 - recall: 0.323 precion/recall curves 1450 / 2000 - precision: 0.443 - recall: 0.329 precion/recall curves 1500 / 2000 - precision: 0.434 - recall: 0.334 precion/recall curves 1550 / 2000 - precision: 0.427 - recall: 0.339 precion/recall curves 1600 / 2000 - precision: 0.421 - recall: 0.346 precion/recall curves 1650 / 2000 - precision: 0.419 - recall: 0.355 precion/recall curves 1700 / 2000 - precision: 0.415 - recall: 0.362 precion/recall curves 1750 / 2000 - precision: 0.410 - recall: 0.368 precion/recall curves 1800 / 2000 - precision: 0.404 - recall: 0.373 precion/recall curves 1850 / 2000 - precision: 0.400 - recall: 0.379 precion/recall curves 1900 / 2000 - precision: 0.392 - recall: 0.382 precion/recall curves 1950 / 2000 - precision: 0.385 - recall: 0.385 precion/recall curves 2000 / 2000 - precision: 0.380 - recall: 0.390 test use time - 00:01:23 模型保存成功, 保存目录为: ./output/ Test end. # Epoch 19/25 - current_alpha: 0.00086892 - loss: 0.137877 - 00:04:07 # Test start... Number of test samples for non NA relation: 1950 precion/recall curves 50 / 2000 - precision: 0.760 - recall: 0.019 precion/recall curves 100 / 2000 - precision: 0.720 - recall: 0.037 precion/recall curves 150 / 2000 - precision: 0.693 - recall: 0.053 precion/recall curves 200 / 2000 - precision: 0.690 - recall: 0.071 precion/recall curves 250 / 2000 - precision: 0.672 - recall: 0.086 precion/recall curves 300 / 2000 - precision: 0.657 - recall: 0.101 precion/recall curves 350 / 2000 - precision: 0.631 - recall: 0.113 precion/recall curves 400 / 2000 - precision: 0.620 - recall: 0.127 precion/recall curves 450 / 2000 - precision: 0.613 - recall: 0.142 precion/recall curves 500 / 2000 - precision: 0.596 - recall: 0.153 precion/recall curves 550 / 2000 - precision: 0.580 - recall: 0.164 precion/recall curves 600 / 2000 - precision: 0.575 - recall: 0.177 precion/recall curves 650 / 2000 - precision: 0.568 - recall: 0.189 precion/recall curves 700 / 2000 - precision: 0.559 - recall: 0.201 precion/recall curves 750 / 2000 - precision: 0.548 - recall: 0.211 precion/recall curves 800 / 2000 - precision: 0.538 - recall: 0.221 precion/recall curves 850 / 2000 - precision: 0.524 - recall: 0.228 precion/recall curves 900 / 2000 - precision: 0.520 - recall: 0.240 precion/recall curves 950 / 2000 - precision: 0.516 - recall: 0.251 precion/recall curves 1000 / 2000 - precision: 0.508 - recall: 0.261 precion/recall curves 1050 / 2000 - precision: 0.504 - recall: 0.271 precion/recall curves 1100 / 2000 - precision: 0.495 - recall: 0.279 precion/recall curves 1150 / 2000 - precision: 0.489 - recall: 0.288 precion/recall curves 1200 / 2000 - precision: 0.484 - recall: 0.298 precion/recall curves 1250 / 2000 - precision: 0.476 - recall: 0.305 precion/recall curves 1300 / 2000 - precision: 0.468 - recall: 0.312 precion/recall curves 1350 / 2000 - precision: 0.463 - recall: 0.321 precion/recall curves 1400 / 2000 - precision: 0.455 - recall: 0.327 precion/recall curves 1450 / 2000 - precision: 0.446 - recall: 0.331 precion/recall curves 1500 / 2000 - precision: 0.441 - recall: 0.339 precion/recall curves 1550 / 2000 - precision: 0.435 - recall: 0.346 precion/recall curves 1600 / 2000 - precision: 0.426 - recall: 0.349 precion/recall curves 1650 / 2000 - precision: 0.422 - recall: 0.357 precion/recall curves 1700 / 2000 - precision: 0.416 - recall: 0.363 precion/recall curves 1750 / 2000 - precision: 0.408 - recall: 0.366 precion/recall curves 1800 / 2000 - precision: 0.402 - recall: 0.371 precion/recall curves 1850 / 2000 - precision: 0.398 - recall: 0.378 precion/recall curves 1900 / 2000 - precision: 0.390 - recall: 0.380 precion/recall curves 1950 / 2000 - precision: 0.385 - recall: 0.385 precion/recall curves 2000 / 2000 - precision: 0.378 - recall: 0.388 test use time - 00:01:22 模型保存成功, 保存目录为: ./output/ Test end. # Epoch 20/25 - current_alpha: 0.00085154 - loss: 0.135148 - 00:04:04 # Test start... Number of test samples for non NA relation: 1950 precion/recall curves 50 / 2000 - precision: 0.760 - recall: 0.019 precion/recall curves 100 / 2000 - precision: 0.750 - recall: 0.038 precion/recall curves 150 / 2000 - precision: 0.700 - recall: 0.054 precion/recall curves 200 / 2000 - precision: 0.670 - recall: 0.069 precion/recall curves 250 / 2000 - precision: 0.664 - recall: 0.085 precion/recall curves 300 / 2000 - precision: 0.653 - recall: 0.101 precion/recall curves 350 / 2000 - precision: 0.640 - recall: 0.115 precion/recall curves 400 / 2000 - precision: 0.625 - recall: 0.128 precion/recall curves 450 / 2000 - precision: 0.613 - recall: 0.142 precion/recall curves 500 / 2000 - precision: 0.600 - recall: 0.154 precion/recall curves 550 / 2000 - precision: 0.580 - recall: 0.164 precion/recall curves 600 / 2000 - precision: 0.575 - recall: 0.177 precion/recall curves 650 / 2000 - precision: 0.562 - recall: 0.187 precion/recall curves 700 / 2000 - precision: 0.551 - recall: 0.198 precion/recall curves 750 / 2000 - precision: 0.544 - recall: 0.209 precion/recall curves 800 / 2000 - precision: 0.526 - recall: 0.216 precion/recall curves 850 / 2000 - precision: 0.518 - recall: 0.226 precion/recall curves 900 / 2000 - precision: 0.511 - recall: 0.236 precion/recall curves 950 / 2000 - precision: 0.501 - recall: 0.244 precion/recall curves 1000 / 2000 - precision: 0.499 - recall: 0.256 precion/recall curves 1050 / 2000 - precision: 0.490 - recall: 0.264 precion/recall curves 1100 / 2000 - precision: 0.484 - recall: 0.273 precion/recall curves 1150 / 2000 - precision: 0.476 - recall: 0.281 precion/recall curves 1200 / 2000 - precision: 0.470 - recall: 0.289 precion/recall curves 1250 / 2000 - precision: 0.464 - recall: 0.297 precion/recall curves 1300 / 2000 - precision: 0.462 - recall: 0.308 precion/recall curves 1350 / 2000 - precision: 0.450 - recall: 0.311 precion/recall curves 1400 / 2000 - precision: 0.441 - recall: 0.316 precion/recall curves 1450 / 2000 - precision: 0.433 - recall: 0.322 precion/recall curves 1500 / 2000 - precision: 0.427 - recall: 0.328 precion/recall curves 1550 / 2000 - precision: 0.423 - recall: 0.336 precion/recall curves 1600 / 2000 - precision: 0.417 - recall: 0.343 precion/recall curves 1650 / 2000 - precision: 0.407 - recall: 0.345 precion/recall curves 1700 / 2000 - precision: 0.405 - recall: 0.353 precion/recall curves 1750 / 2000 - precision: 0.398 - recall: 0.357 precion/recall curves 1800 / 2000 - precision: 0.395 - recall: 0.365 precion/recall curves 1850 / 2000 - precision: 0.391 - recall: 0.371 precion/recall curves 1900 / 2000 - precision: 0.384 - recall: 0.374 precion/recall curves 1950 / 2000 - precision: 0.380 - recall: 0.380 precion/recall curves 2000 / 2000 - precision: 0.375 - recall: 0.385 test use time - 00:01:19 模型保存成功, 保存目录为: ./output/ Test end. # Epoch 21/25 - current_alpha: 0.00083451 - loss: 0.132989 - 00:04:03 # Test start... Number of test samples for non NA relation: 1950 precion/recall curves 50 / 2000 - precision: 0.740 - recall: 0.019 precion/recall curves 100 / 2000 - precision: 0.720 - recall: 0.037 precion/recall curves 150 / 2000 - precision: 0.707 - recall: 0.054 precion/recall curves 200 / 2000 - precision: 0.705 - recall: 0.072 precion/recall curves 250 / 2000 - precision: 0.672 - recall: 0.086 precion/recall curves 300 / 2000 - precision: 0.647 - recall: 0.099 precion/recall curves 350 / 2000 - precision: 0.640 - recall: 0.115 precion/recall curves 400 / 2000 - precision: 0.618 - recall: 0.127 precion/recall curves 450 / 2000 - precision: 0.607 - recall: 0.140 precion/recall curves 500 / 2000 - precision: 0.600 - recall: 0.154 precion/recall curves 550 / 2000 - precision: 0.600 - recall: 0.169 precion/recall curves 600 / 2000 - precision: 0.597 - recall: 0.184 precion/recall curves 650 / 2000 - precision: 0.577 - recall: 0.192 precion/recall curves 700 / 2000 - precision: 0.566 - recall: 0.203 precion/recall curves 750 / 2000 - precision: 0.549 - recall: 0.211 precion/recall curves 800 / 2000 - precision: 0.543 - recall: 0.223 precion/recall curves 850 / 2000 - precision: 0.536 - recall: 0.234 precion/recall curves 900 / 2000 - precision: 0.530 - recall: 0.245 precion/recall curves 950 / 2000 - precision: 0.525 - recall: 0.256 precion/recall curves 1000 / 2000 - precision: 0.519 - recall: 0.266 precion/recall curves 1050 / 2000 - precision: 0.506 - recall: 0.272 precion/recall curves 1100 / 2000 - precision: 0.495 - recall: 0.279 precion/recall curves 1150 / 2000 - precision: 0.489 - recall: 0.288 precion/recall curves 1200 / 2000 - precision: 0.479 - recall: 0.295 precion/recall curves 1250 / 2000 - precision: 0.473 - recall: 0.303 precion/recall curves 1300 / 2000 - precision: 0.468 - recall: 0.312 precion/recall curves 1350 / 2000 - precision: 0.461 - recall: 0.319 precion/recall curves 1400 / 2000 - precision: 0.452 - recall: 0.325 precion/recall curves 1450 / 2000 - precision: 0.443 - recall: 0.329 precion/recall curves 1500 / 2000 - precision: 0.437 - recall: 0.336 precion/recall curves 1550 / 2000 - precision: 0.431 - recall: 0.343 precion/recall curves 1600 / 2000 - precision: 0.423 - recall: 0.347 precion/recall curves 1650 / 2000 - precision: 0.416 - recall: 0.352 precion/recall curves 1700 / 2000 - precision: 0.415 - recall: 0.362 precion/recall curves 1750 / 2000 - precision: 0.411 - recall: 0.369 precion/recall curves 1800 / 2000 - precision: 0.404 - recall: 0.373 precion/recall curves 1850 / 2000 - precision: 0.399 - recall: 0.378 precion/recall curves 1900 / 2000 - precision: 0.394 - recall: 0.384 precion/recall curves 1950 / 2000 - precision: 0.388 - recall: 0.388 precion/recall curves 2000 / 2000 - precision: 0.384 - recall: 0.394 test use time - 00:01:18 模型保存成功, 保存目录为: ./output/ Test end. # Epoch 22/25 - current_alpha: 0.00081782 - loss: 0.130612 - 00:04:07 # Test start... Number of test samples for non NA relation: 1950 precion/recall curves 50 / 2000 - precision: 0.740 - recall: 0.019 precion/recall curves 100 / 2000 - precision: 0.760 - recall: 0.039 precion/recall curves 150 / 2000 - precision: 0.733 - recall: 0.056 precion/recall curves 200 / 2000 - precision: 0.720 - recall: 0.074 precion/recall curves 250 / 2000 - precision: 0.684 - recall: 0.088 precion/recall curves 300 / 2000 - precision: 0.650 - recall: 0.100 precion/recall curves 350 / 2000 - precision: 0.620 - recall: 0.111 precion/recall curves 400 / 2000 - precision: 0.613 - recall: 0.126 precion/recall curves 450 / 2000 - precision: 0.591 - recall: 0.136 precion/recall curves 500 / 2000 - precision: 0.596 - recall: 0.153 precion/recall curves 550 / 2000 - precision: 0.593 - recall: 0.167 precion/recall curves 600 / 2000 - precision: 0.578 - recall: 0.178 precion/recall curves 650 / 2000 - precision: 0.565 - recall: 0.188 precion/recall curves 700 / 2000 - precision: 0.557 - recall: 0.200 precion/recall curves 750 / 2000 - precision: 0.560 - recall: 0.215 precion/recall curves 800 / 2000 - precision: 0.558 - recall: 0.229 precion/recall curves 850 / 2000 - precision: 0.553 - recall: 0.241 precion/recall curves 900 / 2000 - precision: 0.543 - recall: 0.251 precion/recall curves 950 / 2000 - precision: 0.529 - recall: 0.258 precion/recall curves 1000 / 2000 - precision: 0.522 - recall: 0.268 precion/recall curves 1050 / 2000 - precision: 0.518 - recall: 0.279 precion/recall curves 1100 / 2000 - precision: 0.508 - recall: 0.287 precion/recall curves 1150 / 2000 - precision: 0.497 - recall: 0.293 precion/recall curves 1200 / 2000 - precision: 0.484 - recall: 0.298 precion/recall curves 1250 / 2000 - precision: 0.476 - recall: 0.305 precion/recall curves 1300 / 2000 - precision: 0.467 - recall: 0.311 precion/recall curves 1350 / 2000 - precision: 0.460 - recall: 0.318 precion/recall curves 1400 / 2000 - precision: 0.452 - recall: 0.325 precion/recall curves 1450 / 2000 - precision: 0.444 - recall: 0.330 precion/recall curves 1500 / 2000 - precision: 0.439 - recall: 0.338 precion/recall curves 1550 / 2000 - precision: 0.435 - recall: 0.346 precion/recall curves 1600 / 2000 - precision: 0.428 - recall: 0.351 precion/recall curves 1650 / 2000 - precision: 0.419 - recall: 0.355 precion/recall curves 1700 / 2000 - precision: 0.415 - recall: 0.362 precion/recall curves 1750 / 2000 - precision: 0.407 - recall: 0.365 precion/recall curves 1800 / 2000 - precision: 0.399 - recall: 0.368 precion/recall curves 1850 / 2000 - precision: 0.393 - recall: 0.373 precion/recall curves 1900 / 2000 - precision: 0.388 - recall: 0.378 precion/recall curves 1950 / 2000 - precision: 0.384 - recall: 0.384 precion/recall curves 2000 / 2000 - precision: 0.380 - recall: 0.390 test use time - 00:01:19 模型保存成功, 保存目录为: ./output/ Test end. # Epoch 23/25 - current_alpha: 0.00080146 - loss: 0.127765 - 00:03:55 # Test start... Number of test samples for non NA relation: 1950 precion/recall curves 50 / 2000 - precision: 0.740 - recall: 0.019 precion/recall curves 100 / 2000 - precision: 0.740 - recall: 0.038 precion/recall curves 150 / 2000 - precision: 0.700 - recall: 0.054 precion/recall curves 200 / 2000 - precision: 0.690 - recall: 0.071 precion/recall curves 250 / 2000 - precision: 0.676 - recall: 0.087 precion/recall curves 300 / 2000 - precision: 0.653 - recall: 0.101 precion/recall curves 350 / 2000 - precision: 0.637 - recall: 0.114 precion/recall curves 400 / 2000 - precision: 0.627 - recall: 0.129 precion/recall curves 450 / 2000 - precision: 0.616 - recall: 0.142 precion/recall curves 500 / 2000 - precision: 0.604 - recall: 0.155 precion/recall curves 550 / 2000 - precision: 0.584 - recall: 0.165 precion/recall curves 600 / 2000 - precision: 0.562 - recall: 0.173 precion/recall curves 650 / 2000 - precision: 0.557 - recall: 0.186 precion/recall curves 700 / 2000 - precision: 0.543 - recall: 0.195 precion/recall curves 750 / 2000 - precision: 0.537 - recall: 0.207 precion/recall curves 800 / 2000 - precision: 0.531 - recall: 0.218 precion/recall curves 850 / 2000 - precision: 0.529 - recall: 0.231 precion/recall curves 900 / 2000 - precision: 0.526 - recall: 0.243 precion/recall curves 950 / 2000 - precision: 0.519 - recall: 0.253 precion/recall curves 1000 / 2000 - precision: 0.503 - recall: 0.258 precion/recall curves 1050 / 2000 - precision: 0.494 - recall: 0.266 precion/recall curves 1100 / 2000 - precision: 0.489 - recall: 0.276 precion/recall curves 1150 / 2000 - precision: 0.483 - recall: 0.285 precion/recall curves 1200 / 2000 - precision: 0.477 - recall: 0.293 precion/recall curves 1250 / 2000 - precision: 0.466 - recall: 0.298 precion/recall curves 1300 / 2000 - precision: 0.456 - recall: 0.304 precion/recall curves 1350 / 2000 - precision: 0.448 - recall: 0.310 precion/recall curves 1400 / 2000 - precision: 0.443 - recall: 0.318 precion/recall curves 1450 / 2000 - precision: 0.434 - recall: 0.323 precion/recall curves 1500 / 2000 - precision: 0.429 - recall: 0.330 precion/recall curves 1550 / 2000 - precision: 0.425 - recall: 0.337 precion/recall curves 1600 / 2000 - precision: 0.420 - recall: 0.345 precion/recall curves 1650 / 2000 - precision: 0.415 - recall: 0.351 precion/recall curves 1700 / 2000 - precision: 0.409 - recall: 0.356 precion/recall curves 1750 / 2000 - precision: 0.402 - recall: 0.361 precion/recall curves 1800 / 2000 - precision: 0.397 - recall: 0.366 precion/recall curves 1850 / 2000 - precision: 0.391 - recall: 0.371 precion/recall curves 1900 / 2000 - precision: 0.387 - recall: 0.377 precion/recall curves 1950 / 2000 - precision: 0.383 - recall: 0.383 precion/recall curves 2000 / 2000 - precision: 0.377 - recall: 0.387 test use time - 00:01:19 模型保存成功, 保存目录为: ./output/ Test end. # Epoch 24/25 - current_alpha: 0.00078543 - loss: 0.124412 - 00:03:38 # Test start... Number of test samples for non NA relation: 1950 precion/recall curves 50 / 2000 - precision: 0.740 - recall: 0.019 precion/recall curves 100 / 2000 - precision: 0.720 - recall: 0.037 precion/recall curves 150 / 2000 - precision: 0.720 - recall: 0.055 precion/recall curves 200 / 2000 - precision: 0.700 - recall: 0.072 precion/recall curves 250 / 2000 - precision: 0.692 - recall: 0.089 precion/recall curves 300 / 2000 - precision: 0.657 - recall: 0.101 precion/recall curves 350 / 2000 - precision: 0.654 - recall: 0.117 precion/recall curves 400 / 2000 - precision: 0.640 - recall: 0.131 precion/recall curves 450 / 2000 - precision: 0.611 - recall: 0.141 precion/recall curves 500 / 2000 - precision: 0.612 - recall: 0.157 precion/recall curves 550 / 2000 - precision: 0.593 - recall: 0.167 precion/recall curves 600 / 2000 - precision: 0.580 - recall: 0.178 precion/recall curves 650 / 2000 - precision: 0.571 - recall: 0.190 precion/recall curves 700 / 2000 - precision: 0.556 - recall: 0.199 precion/recall curves 750 / 2000 - precision: 0.549 - recall: 0.211 precion/recall curves 800 / 2000 - precision: 0.549 - recall: 0.225 precion/recall curves 850 / 2000 - precision: 0.541 - recall: 0.236 precion/recall curves 900 / 2000 - precision: 0.537 - recall: 0.248 precion/recall curves 950 / 2000 - precision: 0.527 - recall: 0.257 precion/recall curves 1000 / 2000 - precision: 0.515 - recall: 0.264 precion/recall curves 1050 / 2000 - precision: 0.507 - recall: 0.273 precion/recall curves 1100 / 2000 - precision: 0.501 - recall: 0.283 precion/recall curves 1150 / 2000 - precision: 0.489 - recall: 0.288 precion/recall curves 1200 / 2000 - precision: 0.482 - recall: 0.296 precion/recall curves 1250 / 2000 - precision: 0.474 - recall: 0.304 precion/recall curves 1300 / 2000 - precision: 0.461 - recall: 0.307 precion/recall curves 1350 / 2000 - precision: 0.456 - recall: 0.315 precion/recall curves 1400 / 2000 - precision: 0.448 - recall: 0.322 precion/recall curves 1450 / 2000 - precision: 0.439 - recall: 0.326 precion/recall curves 1500 / 2000 - precision: 0.432 - recall: 0.332 precion/recall curves 1550 / 2000 - precision: 0.428 - recall: 0.341 precion/recall curves 1600 / 2000 - precision: 0.424 - recall: 0.348 precion/recall curves 1650 / 2000 - precision: 0.415 - recall: 0.351 precion/recall curves 1700 / 2000 - precision: 0.410 - recall: 0.357 precion/recall curves 1750 / 2000 - precision: 0.406 - recall: 0.365 precion/recall curves 1800 / 2000 - precision: 0.400 - recall: 0.369 precion/recall curves 1850 / 2000 - precision: 0.395 - recall: 0.374 precion/recall curves 1900 / 2000 - precision: 0.392 - recall: 0.382 precion/recall curves 1950 / 2000 - precision: 0.389 - recall: 0.389 precion/recall curves 2000 / 2000 - precision: 0.383 - recall: 0.393 test use time - 00:01:19 模型保存成功, 保存目录为: ./output/ Test end. # Epoch 25/25 - current_alpha: 0.00076973 - loss: 0.124694 - 00:04:05 # Test start... Number of test samples for non NA relation: 1950 precion/recall curves 50 / 2000 - precision: 0.760 - recall: 0.019 precion/recall curves 100 / 2000 - precision: 0.730 - recall: 0.037 precion/recall curves 150 / 2000 - precision: 0.720 - recall: 0.055 precion/recall curves 200 / 2000 - precision: 0.715 - recall: 0.073 precion/recall curves 250 / 2000 - precision: 0.692 - recall: 0.089 precion/recall curves 300 / 2000 - precision: 0.657 - recall: 0.101 precion/recall curves 350 / 2000 - precision: 0.634 - recall: 0.114 precion/recall curves 400 / 2000 - precision: 0.623 - recall: 0.128 precion/recall curves 450 / 2000 - precision: 0.611 - recall: 0.141 precion/recall curves 500 / 2000 - precision: 0.590 - recall: 0.151 precion/recall curves 550 / 2000 - precision: 0.587 - recall: 0.166 precion/recall curves 600 / 2000 - precision: 0.577 - recall: 0.177 precion/recall curves 650 / 2000 - precision: 0.565 - recall: 0.188 precion/recall curves 700 / 2000 - precision: 0.551 - recall: 0.198 precion/recall curves 750 / 2000 - precision: 0.540 - recall: 0.208 precion/recall curves 800 / 2000 - precision: 0.533 - recall: 0.218 precion/recall curves 850 / 2000 - precision: 0.519 - recall: 0.226 precion/recall curves 900 / 2000 - precision: 0.520 - recall: 0.240 precion/recall curves 950 / 2000 - precision: 0.511 - recall: 0.249 precion/recall curves 1000 / 2000 - precision: 0.501 - recall: 0.257 precion/recall curves 1050 / 2000 - precision: 0.492 - recall: 0.265 precion/recall curves 1100 / 2000 - precision: 0.484 - recall: 0.273 precion/recall curves 1150 / 2000 - precision: 0.477 - recall: 0.282 precion/recall curves 1200 / 2000 - precision: 0.469 - recall: 0.289 precion/recall curves 1250 / 2000 - precision: 0.468 - recall: 0.300 precion/recall curves 1300 / 2000 - precision: 0.463 - recall: 0.309 precion/recall curves 1350 / 2000 - precision: 0.454 - recall: 0.314 precion/recall curves 1400 / 2000 - precision: 0.449 - recall: 0.323 precion/recall curves 1450 / 2000 - precision: 0.440 - recall: 0.327 precion/recall curves 1500 / 2000 - precision: 0.436 - recall: 0.335 precion/recall curves 1550 / 2000 - precision: 0.428 - recall: 0.341 precion/recall curves 1600 / 2000 - precision: 0.426 - recall: 0.350 precion/recall curves 1650 / 2000 - precision: 0.419 - recall: 0.354 precion/recall curves 1700 / 2000 - precision: 0.413 - recall: 0.360 precion/recall curves 1750 / 2000 - precision: 0.406 - recall: 0.365 precion/recall curves 1800 / 2000 - precision: 0.398 - recall: 0.368 precion/recall curves 1850 / 2000 - precision: 0.395 - recall: 0.374 precion/recall curves 1900 / 2000 - precision: 0.389 - recall: 0.379 precion/recall curves 1950 / 2000 - precision: 0.383 - recall: 0.383 precion/recall curves 2000 / 2000 - precision: 0.379 - recall: 0.389 test use time - 00:01:19 模型保存成功, 保存目录为: ./output/ Test end. # Train end. # $ tree . ├── build │ ├── test │ └── train ├── clean.sh ├── init.h ├── output │ ├── attention_weights.txt │ ├── conv_1d.txt │ ├── position_vec.txt │ ├── pr.txt │ ├── relation_matrix.txt │ └── word2vec.txt ├── run.sh ├── test.cpp ├── test.h └── train.cpp 2 directories, 14 files $ bash clean.sh # ./build 目录递归删除成功. # $ tree . ├── clean.sh ├── init.h ├── output │ ├── attention_weights.txt │ ├── conv_1d.txt │ ├── position_vec.txt │ ├── pr.txt │ ├── relation_matrix.txt │ └── word2vec.txt ├── run.sh ├── test.cpp ├── test.h └── train.cpp 1 directory, 12 files $
训练和测试的参数
train.cpp
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 // ./train [-batch BATCH] [-threads THREAD] [-alpha ALPHA] // [-init_rate INIT_RATE] [-reduce_epoch REDUCE_EPOCH] // [-epochs EPOCHS] [-limit LIMIT] [-dimension_pos DIMENSION_POS] // [-window WINDOW] [-dimension_c DIMENSION_C] // [-dropout DROPOUT] [-output_model 0/1] // [-note NOTE] [-data_path DATA_PATH] // [-output_path OUTPUT_PATH] [--help] // optional arguments: // -batch BATCH batch size. if unspecified, batch will default to [40] // -threads THREAD number of worker threads. if unspecified, num_threads will default to [32] // -alpha ALPHA learning rate. if unspecified, alpha will default to [0.00125] // -init_rate INIT_RATE init rate of learning rate. if unspecified, current_rate will default to [1.0] // -reduce_epoch REDUCE_EPOCH reduce of init rate of learning rate per epoch. if unspecified, reduce_epoch will default to [0.98] // -epochs EPOCHS number of epochs. if unspecified, epochs will default to [25] // -limit LIMIT 限制句子中 (头, 尾) 实体相对每个单词的最大距离. 默认值为 [30] // -dimension_pos DIMENSION_POS 位置嵌入维度,默认值为 [5] // -window WINDOW 一维卷积的 window 大小. 默认值为 [3] // -dimension_c DIMENSION_C sentence embedding size, if unspecified, dimension_c will default to [230] // -dropout DROPOUT dropout probability. if unspecified, dropout_probability will default to [0.5] // -output_model 0/1 [1] 保存模型, [0] 不保存模型. 默认值为 [1] // -note NOTE information you want to add to the filename, like ("./output/word2vec" + note + ".txt"). if unspecified, note will default to "" // -data_path DATA_PATH folder of data. if unspecified, data_path will default to "../data/" // -output_path OUTPUT_PATH folder of outputing results (precion/recall curves) and models. if unspecified, output_path will default to "./output/" // --help print help information of ./train
test.cpp
1 2 3 4 5 6 7 8 9 10 // ./test [-threads THREAD] [-dropout DROPOUT] // [-note NOTE] [-data_path DATA_PATH] // [-load_path LOAD_PATH] [--help] // optional arguments: // -threads THREAD number of worker threads. if unspecified, num_threads will default to [32] // -note NOTE information you want to add to the filename, like ("./output/word2vec" + note + ".txt"). if unspecified, note will default to "" // -data_path DATA_PATH folder of data. if unspecified, data_path will default to "../data/" // -load_path LOAD_PATH folder of pretrained models. if unspecified, load_path will default to "./output/" // --help print help information of ./test
结语
第三十六篇博文写完,开心!!!!
今天,也是充满希望的一天。

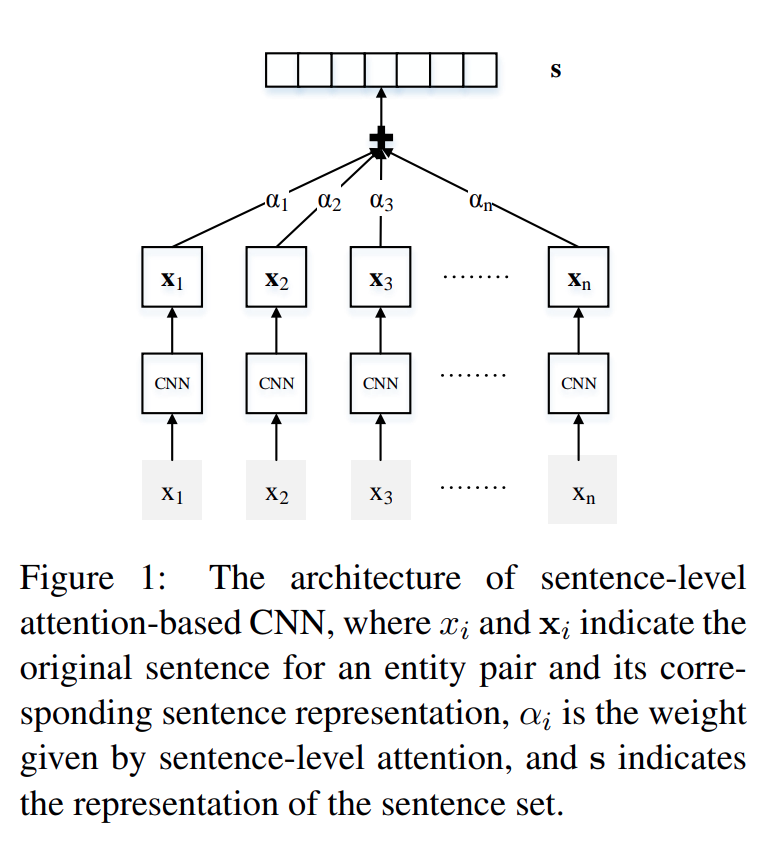
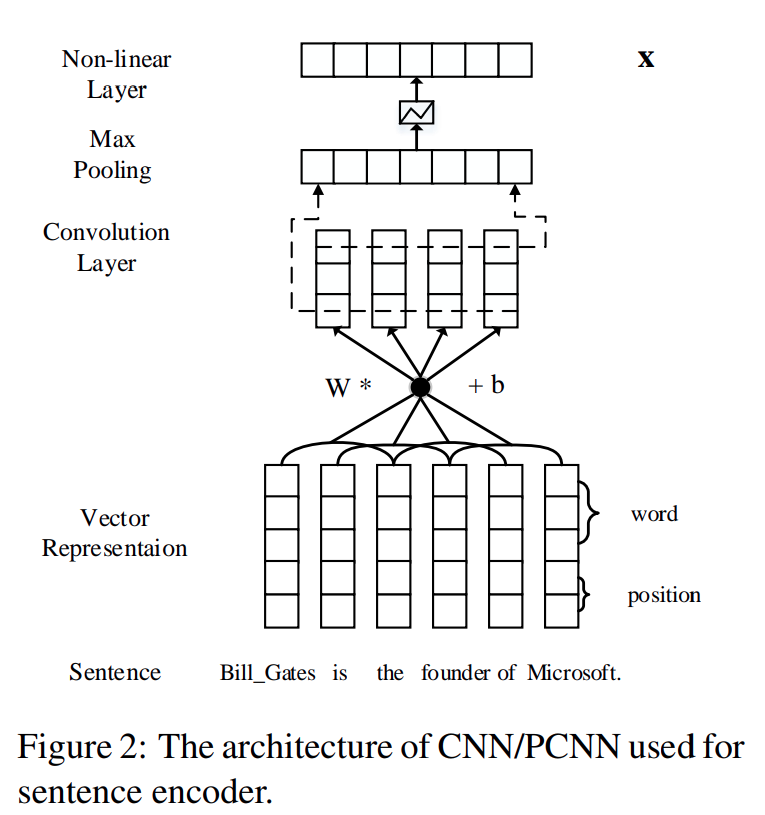
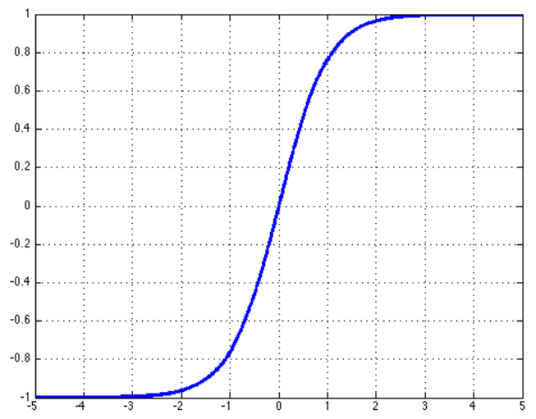
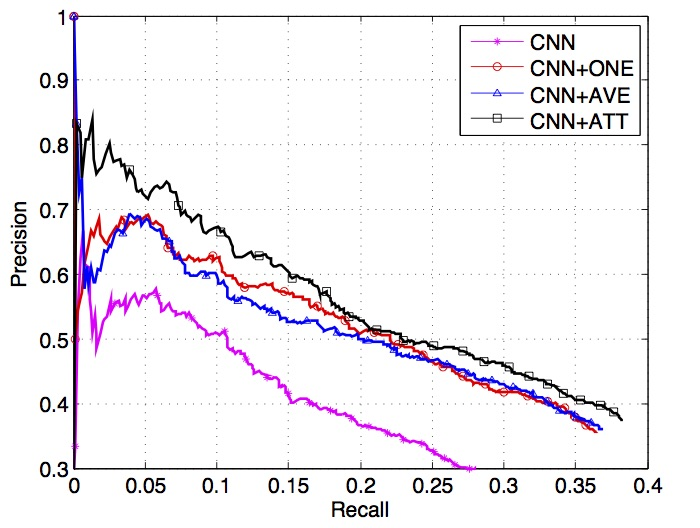
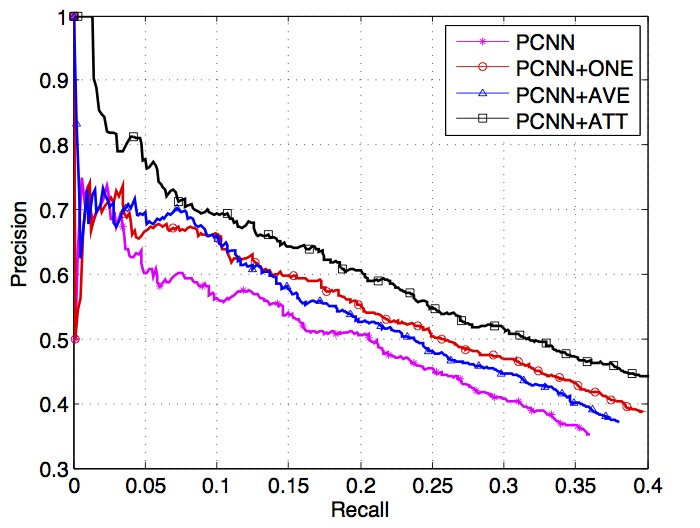
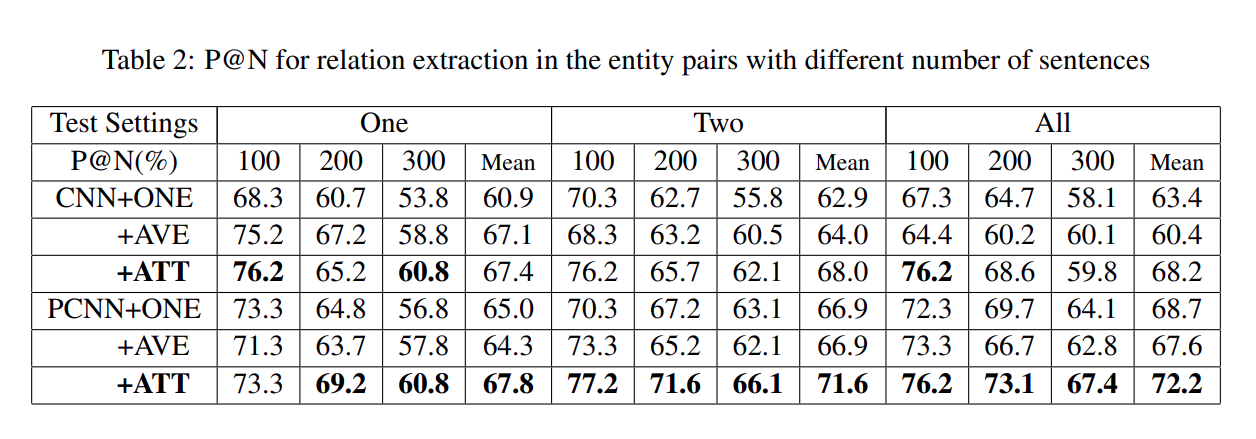
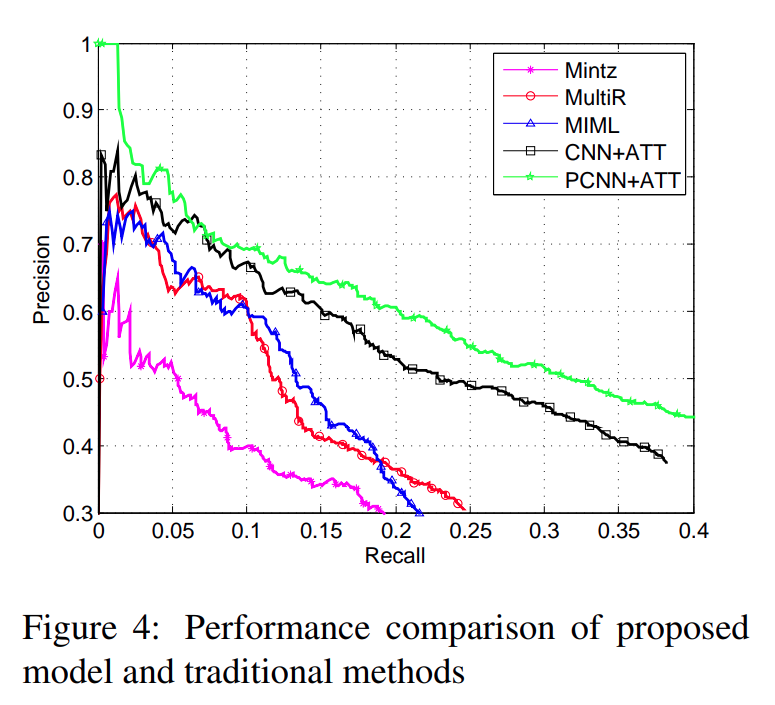

 wechat
wechat alipay
alipay










