If you use the code, please cite the following paper:
1 2 3 4 5 6
@inproceedings{han2018openke, title={OpenKE: An Open Toolkit for Knowledge Embedding}, author={Han, Xu and Cao, Shulin and Lv Xin and Lin, Yankai and Liu, Zhiyuan and Sun, Maosong and Li, Juanzi}, booktitle={Proceedings of EMNLP}, year={2018} }
Overview
This is an Efficient implementation based on PyTorch for knowledge representation learning (KRL). We use C++ to implement some underlying operations such as data preprocessing and negative sampling. For each specific model, it is implemented by PyTorch with Python interfaces so that there is a convenient platform to run models on GPUs. OpenKE composes 4 repositories:
OpenKE-PyTorch: the project based on PyTorch, which provides the optimized and stable framework for knowledge graph embedding models.
OpenKE-Tensorflow1.0: OpenKE implemented with TensorFlow, also providing the optimized and stable framework for knowledge graph embedding models.
TensorFlow-TransX: light and simple version of OpenKE based on TensorFlow, including TransE, TransH, TransR and TransD.
Fast-TransX: efficient lightweight C++ inferences for TransE and its extended models utilizing the framework of OpenKE, including TransH, TransR, TransD, TranSparse and PTransE.
We are now developing a new version of OpenKE-PyTorch. The project has been completely reconstructed and is faster, more extendable and the codes are easier to read and use now. If you need get to the old version, please refer to branch OpenKE-PyTorch(old).
New Features
RotatE
More enhancing strategies (e.g., adversarial training)
More scripts of the typical models for the benchmark datasets.
For each test triplet, the head is removed and replaced by each of the entities from the entity set in turn. The scores of those corrupted triplets are first computed by the models and then sorted by the order. Then, we get the rank of the correct entity. This whole procedure is also repeated by removing those tail entities. We report the proportion of those correct entities ranked in the top 10/3/1 (Hits@10, Hits@3, Hits@1). The mean rank (MRR) and mean reciprocal rank (MRR) of the test triplets under this setting are also reported.
Because some corrupted triplets may be in the training set and validation set. In this case, those corrupted triplets may be ranked above the test triplet, but this should not be counted as an error because both triplets are true. Hence, we remove those corrupted triplets appearing in the training, validation or test set, which ensures the corrupted triplets are not in the dataset. We report the proportion of those correct entities ranked in the top 10/3/1 (Hits@10 (filter), Hits@3(filter), Hits@1(filter)) under this setting. The mean rank (MRR (filter)) and mean reciprocal rank (MRR (filter)) of the test triplets under this setting are also reported.
More details of the above-mentioned settings can be found from the papers TransE, ComplEx.
For those large-scale entity sets, to corrupt all entities with the whole entity set is time-costing. Hence, we also provide the experimental setting named “type constraint” to corrupt entities with some limited entity sets determining by their relations.
Experiments
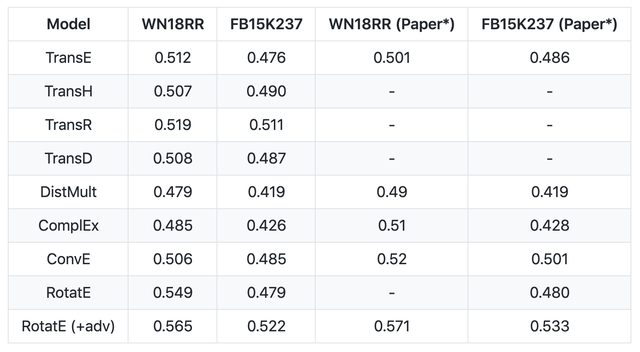
We have provided the hyper-parameters of some models to achieve the state-of-the-art performace (Hits@10 (filter)) on FB15K237 and WN18RR. These scripts can be founded in the folder "./examples/". Up to now, these models include TransE, TransH, TransR, TransD, DistMult, ComplEx. The results of these models are as follows:
Model
WN18RR
FB15K237
WN18RR (Paper*)
FB15K237 (Paper*)
TransE
0.512
0.476
0.501
0.486
TransH
0.507
0.490
-
-
TransR
0.519
0.511
-
-
TransD
0.508
0.487
-
-
DistMult
0.479
0.419
0.49
0.419
ComplEx
0.485
0.426
0.51
0.428
ConvE
0.506
0.485
0.52
0.501
RotatE
0.549
0.479
-
0.480
RotatE (+adv)
0.565
0.522
0.571
0.533
We are still trying more hyper-parameters and more training strategies (e.g., adversarial training and label smoothing regularization) for these models. Hence, this table is still in change. We welcome everyone to help us update this table and hyper-parameters.
git clone -b OpenKE-PyTorch https://github.com/thunlp/OpenKE --depth 1 cd OpenKE cd openke
Compile C++ files
1
bash make.sh
Quick Start
1 2 3
cd ../ cp examples/train_transe_FB15K237.py ./ python train_transe_FB15K237.py
Data
For training, datasets contain three files:
train2id.txt: training file, the first line is the number of triples for training. Then the following lines are all in the format (e1, e2, rel) which indicates there is a relation rel between e1 and e2 . Note that train2id.txt contains ids from entitiy2id.txt and relation2id.txt instead of the names of the entities and relations. If you use your own datasets, please check the format of your training file. Files in the wrong format may cause segmentation fault.
entity2id.txt: all entities and corresponding ids, one per line. The first line is the number of entities.
relation2id.txt: all relations and corresponding ids, one per line. The first line is the number of relations.
For testing, datasets contain additional two files (totally five files):
test2id.txt: testing file, the first line is the number of triples for testing. Then the following lines are all in the format (e1, e2, rel).
valid2id.txt: validating file, the first line is the number of triples for validating. Then the following lines are all in the format (e1, e2, rel) .
type_constrain.txt: type constraining file, the first line is the number of relations. Then the following lines are type constraints for each relation. For example, the relation with id 1200 has 4 types of head entities, which are 3123, 1034, 58 and 5733. The relation with id 1200 has 4 types of tail entities, which are 12123, 4388, 11087 and 11088. You can get this file through n-n.py in folder benchmarks/FB15K.
To do
The document of the new version of OpenKE-PyTorch will come soon.
import openke from openke.config import Trainer, Tester from openke.module.model import Analogy from openke.module.loss import SoftplusLoss from openke.module.strategy import NegativeSampling from openke.data import TrainDataLoader, TestDataLoader
# dataloader for test test_dataloader = TestDataLoader("./benchmarks/WN18RR/", "link")
# define the model analogy = Analogy( ent_tot = train_dataloader.get_ent_tot(), rel_tot = train_dataloader.get_rel_tot(), dim = 200 )
# define the loss function model = NegativeSampling( model = analogy, loss = SoftplusLoss(), batch_size = train_dataloader.get_batch_size(), regul_rate = 1.0 )
import openke from openke.config import Trainer, Tester from openke.module.model import ComplEx from openke.module.loss import SoftplusLoss from openke.module.strategy import NegativeSampling from openke.data import TrainDataLoader, TestDataLoader
# dataloader for test test_dataloader = TestDataLoader("./benchmarks/WN18RR/", "link")
# define the model complEx = ComplEx( ent_tot = train_dataloader.get_ent_tot(), rel_tot = train_dataloader.get_rel_tot(), dim = 200 )
# define the loss function model = NegativeSampling( model = complEx, loss = SoftplusLoss(), batch_size = train_dataloader.get_batch_size(), regul_rate = 1.0 )
import openke from openke.config import Trainer, Tester from openke.module.model import DistMult from openke.module.loss import SoftplusLoss from openke.module.strategy import NegativeSampling from openke.data import TrainDataLoader, TestDataLoader
# dataloader for test test_dataloader = TestDataLoader("./benchmarks/WN18RR/", "link")
# define the model distmult = DistMult( ent_tot = train_dataloader.get_ent_tot(), rel_tot = train_dataloader.get_rel_tot(), dim = 200 )
# define the loss function model = NegativeSampling( model = distmult, loss = SoftplusLoss(), batch_size = train_dataloader.get_batch_size(), regul_rate = 1.0 )
import openke from openke.config import Trainer, Tester from openke.module.model import DistMult from openke.module.loss import SigmoidLoss from openke.module.strategy import NegativeSampling from openke.data import TrainDataLoader, TestDataLoader
# dataloader for test test_dataloader = TestDataLoader("./benchmarks/WN18RR/", "link")
# define the model distmult = DistMult( ent_tot = train_dataloader.get_ent_tot(), rel_tot = train_dataloader.get_rel_tot(), dim = 1024, margin = 200.0, epsilon = 2.0 )
# define the loss function model = NegativeSampling( model = distmult, loss = SigmoidLoss(adv_temperature = 0.5), batch_size = train_dataloader.get_batch_size(), l3_regul_rate = 0.000005 )
import openke from openke.config import Trainer, Tester from openke.module.model import HolE from openke.module.loss import SoftplusLoss from openke.module.strategy import NegativeSampling from openke.data import TrainDataLoader, TestDataLoader
# dataloader for test test_dataloader = TestDataLoader("./benchmarks/WN18RR/", "link")
# define the model hole = HolE( ent_tot = train_dataloader.get_ent_tot(), rel_tot = train_dataloader.get_rel_tot(), dim = 100 )
# define the loss function model = NegativeSampling( model = hole, loss = SoftplusLoss(), batch_size = train_dataloader.get_batch_size(), regul_rate = 1.0 )
import openke from openke.config import Trainer, Tester from openke.module.model import RESCAL from openke.module.loss import MarginLoss from openke.module.strategy import NegativeSampling from openke.data import TrainDataLoader, TestDataLoader
# dataloader for test test_dataloader = TestDataLoader("./benchmarks/FB15K237/", "link")
# define the model rescal = RESCAL( ent_tot = train_dataloader.get_ent_tot(), rel_tot = train_dataloader.get_rel_tot(), dim = 50 )
# define the loss function model = NegativeSampling( model = rescal, loss = MarginLoss(margin = 1.0), batch_size = train_dataloader.get_batch_size(), )
import openke from openke.config import Trainer, Tester from openke.module.model import RotatE from openke.module.loss import SigmoidLoss from openke.module.strategy import NegativeSampling from openke.data import TrainDataLoader, TestDataLoader
# dataloader for test test_dataloader = TestDataLoader("./benchmarks/WN18RR/", "link")
# define the model rotate = RotatE( ent_tot = train_dataloader.get_ent_tot(), rel_tot = train_dataloader.get_rel_tot(), dim = 1024, margin = 6.0, epsilon = 2.0, )
# define the loss function model = NegativeSampling( model = rotate, loss = SigmoidLoss(adv_temperature = 2), batch_size = train_dataloader.get_batch_size(), regul_rate = 0.0 )
import openke from openke.config import Trainer, Tester from openke.module.model import SimplE from openke.module.loss import SoftplusLoss from openke.module.strategy import NegativeSampling from openke.data import TrainDataLoader, TestDataLoader
# dataloader for test test_dataloader = TestDataLoader("./benchmarks/WN18RR/", "link")
# define the model simple = SimplE( ent_tot = train_dataloader.get_ent_tot(), rel_tot = train_dataloader.get_rel_tot(), dim = 200 )
# define the loss function model = NegativeSampling( model = simple, loss = SoftplusLoss(), batch_size = train_dataloader.get_batch_size(), regul_rate = 1.0 )
import openke from openke.config import Trainer, Tester from openke.module.model import TransD from openke.module.loss import MarginLoss from openke.module.strategy import NegativeSampling from openke.data import TrainDataLoader, TestDataLoader
import openke from openke.config import Trainer, Tester from openke.module.model import TransE from openke.module.loss import MarginLoss from openke.module.strategy import NegativeSampling from openke.data import TrainDataLoader, TestDataLoader
import openke from openke.config import Trainer, Tester from openke.module.model import TransE from openke.module.loss import SigmoidLoss from openke.module.strategy import NegativeSampling from openke.data import TrainDataLoader, TestDataLoader
# dataloader for test test_dataloader = TestDataLoader("./benchmarks/WN18RR/", "link")
# define the model transe = TransE( ent_tot = train_dataloader.get_ent_tot(), rel_tot = train_dataloader.get_rel_tot(), dim = 1024, p_norm = 1, norm_flag = False, margin = 6.0)
# define the loss function model = NegativeSampling( model = transe, loss = SigmoidLoss(adv_temperature = 1), batch_size = train_dataloader.get_batch_size(), regul_rate = 0.0 )
import openke from openke.config import Trainer, Tester from openke.module.model import TransH from openke.module.loss import MarginLoss from openke.module.strategy import NegativeSampling from openke.data import TrainDataLoader, TestDataLoader
import openke from openke.config import Trainer, Tester from openke.module.model import TransE, TransR from openke.module.loss import MarginLoss from openke.module.strategy import NegativeSampling from openke.data import TrainDataLoader, TestDataLoader

 wechat
wechat alipay
alipay

.png)








